En matière de conception de robot de trading, on pourrait identifier 2 approches principales qui semblent être en opposition.
La première tend à rechercher un “alpha” optimum, c’est à dire un ensemble de quelques critères (généralement moins de 10), qui permettraient de générer des trades globalement favorables et qui ainsi se suffiraient à eux-mêmes. Dans cette approche, on voit d’un mauvais œil toute tentative d’optimisation qui ferait prendre systématiquement un risque trop grand d’over-fitting (suroptimisation de la phase d’entraînement avec dégradation des performances lors du passage en réel).
Cette approche pourrait être comparée à la recherche d’une aiguille dans une botte de foin. Une recherche souvent longue avant d’aboutir à une formule suffisamment robuste pour garantir des revenus quelles que soient les conditions de marché. Cette quête du Graal, toutefois, si elle se concrétise, permet par la suite de mettre en œuvre un robot d’une simplicité déconcertante…
Cette approche requiert beaucoup de patience, et de curiosité. Il faut également savoir qu’un alpha peut être non rentable sur un actif donné, mais générer des profits réguliers sur un autre pourtant proche. Une systématisation des tests sur des dizaines, voire des centaines d’actifs peut donc s’avérer être une stratégie payante.
“Amateurs develop individual strategies, believing that there is such a thing as a magical formula for riches. In contrast, professionals develop methods to mass-produce strategies. The money is not in making a car, it is in making a car factory.
Marcos Lopez de Prado – Advances en Financial Machine Learning
Think like a business. Your goal is to run a research lab like a factory, where true discoveries are not born out of inspiration, but out of methodic hard work. That was the philosophy of physicist Ernest Lawrence, the founder of the first U.S. National Laboratory”
La deuxième approche tend à considérer qu’il est inutile de chercher à modéliser par un moyen simple un problème aussi complexe que des données financières. A problème complexe, solution complexe. Il s’agit donc ici de chercher une stratégie brute acceptable, c’est à dire générant suffisamment de signaux gagnants (et perdants), sans forcément se préoccuper dans un premier temps de savoir si cette stratégie brute est gagnante ou pas. Bien entendu, plus la performance initiale est bonne, et moins il y aura de travail par la suite.
Il ne s’agit alors plus de creuser indéfiniment à la recherche d’un diamant déjà taillé, mais plutôt de partir d’un diamant brut et de le tailler soi-même (ce qui implique d’apprendre à tailler un diamant!).
Le travail d’optimisation qui va alors s’en suivre va chercher à soustraire des trades générés le plus possible de trades perdants, ce qui va permettre d’augmenter le WinRate. En langage de machine learning, on part d’une stratégie brute avec une précision moyenne à faible, mais avec un bon recall, puis on cherche à améliorer la précision sans détériorer le facteur recall (en d’autres termes, on veut abaisser le nombre de faux positifs, tout en maintenant élevé le nombre de vrais positifs).
Bien entendu, les modèles de machine learning/deep learning rentrent dans cette catégorie.
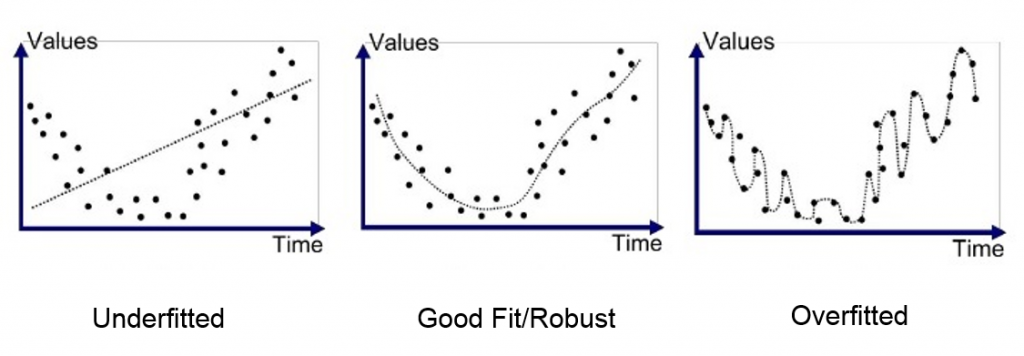
Over-fitting vs under-fitting
Si dans la première approche décrite précédemment, le risque d’over-fitting est nul (puisqu’il n’y a pas eu d’étape d’optimisation poussée), le risque d’under-fitting est quant à lui élevé. En somme, une telle stratégie va très probablement émettre des trades dans des configurations de marché que tout analyste technique aurait pu qualifier à l’avance de très probablement défavorable. Des pertes évitables auront donc lieu régulièrement, ce qui peut s’avérer assez frustrant.
Dans la deuxième approche, l’optimisation va quant à elle faire effectivement prendre le risque d’over-fitting, problème qu’il est important de prendre très au sérieux. A mes débuts, j’étais capable de produire des résultats de simulation quasi linéaires, avec 90% de trades gagnants, des performances incroyables, et pourtant, lors du passage sur des données en temps réel, c’était la désillusion la plus totale. Cela signifie-t-il qu’il faille éviter totalement toute phase d’optimisation? Je ne le pense pas. Il est par contre nécessaire d’essayer de comprendre l’over-fitting, afin de le limiter au maximum.
Des données en quantité suffisante
Le premier conseil est de disposer de données en quantité suffisante. On peut généralement trouver gratuitement des historiques sur 10 ans pour les indices, forex, matières premières. Bien plus si vous vous intéressez aux actions. Avec le recul, un historique de 10 ans me semble insuffisant. Vous pouvez essayer de vous procurer des historiques plus anciens, ce qui sera probablement payant. Vous pouvez également, et c’est également une bonne pratique, optimiser votre robot sur la base des données de plusieurs actifs proches. Plusieurs paires de devises si vous êtes sur le forex, ou plusieurs indices si vous êtes sur les indices.
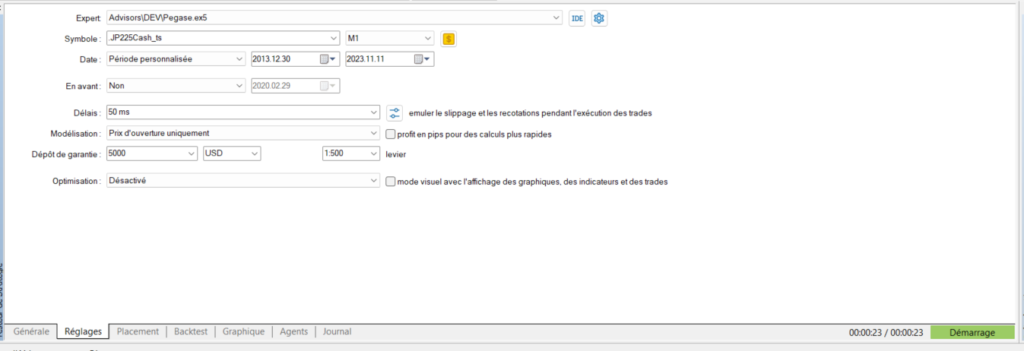
A titre d’exemple mon dernier robot Pegase est optimisé/testé sur 5 indices : DowJones, Dax, SP500, Nasdaq, JP225. Un dernier indice, le CAC40 est utilisé pour la validation/évaluation des performances.
Donc plus on a de données, mieux c’est.
Bien entendu, il faudra prendre soin de normaliser nos données afin de pouvoir comparer plusieurs actifs entre eux.
Ne pas trop descendre dans les échelles de temps
Mon deuxième conseil est de rester le plus général possible lors de l’écriture d’un critère, ce qui implique notamment de ne pas descendre dans les échelles de temps. Avec l’expérience, on s’aperçoit que la description d’une configuration de marché sur la base des graphes MN1, W1 et D1 suffit le plus souvent. Plus on descend, et plus on rentre dans une description très spécifique qui aura peu de chances de se reproduire un jour. Et plus on descend, plus le “bruit” occupera une place importante par rapport à l’information véritable.
Faire varier les seuils
L’objectif de l’optimisation est d’arriver à décrire des configurations de marché qui se reproduisent régulièrement dans le temps, avec des résultats comparables à chaque fois. Cette capacité à identifier les “features” les plus appropriées et à écrire les bons critères se développe bien entendu avec l’expérience.
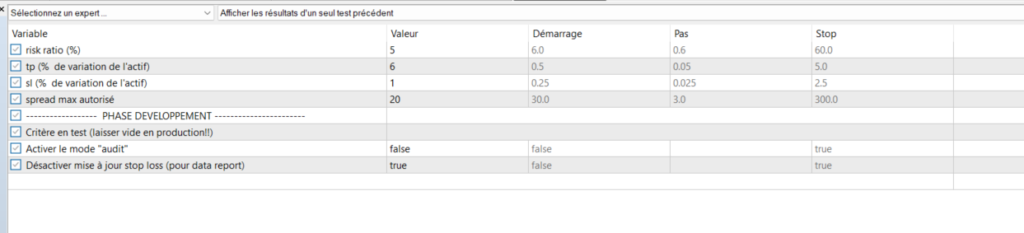
Une bonne pratique consiste toutefois à faire varier les seuils que l’on peut être amené à utiliser. Par exemple, si l’on veut quantifier la force d’un gradient de moyenne mobile, ou bien l’éloignement du prix par rapport à une bande de bollinger ou à une moyenne mobile, on peut être amené à utiliser une valeur seuil. On va ainsi s’apercevoir par exemple que si notre gradient de moyenne mobile est supérieur à X, et le prix est inférieur à Y par rapport à cette moyenne mobile, il devient dangereux de vendre car nous constatons une majorité de trades perdants. Mais que se passe-t-il si nous faisons varier X et Y de quelques points? Si la proportion de trades perdants reste très majoritaire, alors nous pourrons peut-être en conclure que ces critères se suffisent à eux-mêmes. Par contre si nous voyons apparaître des trades gagnants intéressants, alors nous allons peut-être en conclure que l’ajout de nouveaux critères, tels que le stochastique ou autre, est nécessaire.
Pour conclure, je dirai que le choix entre les 2 approches vous appartient, mais que les 2 peuvent donner de bons résultats, à condition d’avoir bien conscience des notions d’over-fitting/under-fitting.
Si le machine learning a le vent en poupe ces dernières années concernant la prédiction de données financières et que de nombreuses recherches sont menées dans ce domaine, les solutions simples et toutes faîtes ne sont pas aussi évidentes. Ce n’est pas parce que vous allez mettre en œuvre un algorithme Random Forest rapidement sur votre jeu de données, avec quelques features prises au hasard, que vous pouvez espérer rapidement de bons résultats sans vous soucier de ce que fait l’algorithme.
Passer du temps à analyser les marchés, écrire des critères à la main pour voir concrètement ce que cela donne, et au fil du temps identifier des patterns qui fonctionnent est une première étape qui me semble indispensable.
Pour alimenter votre algorithme de machine learning avec les bonnes informations, encore faut-il savoir quelles sont ces “bonnes informations”.

Dans un prochain article j’introduirais mon algorithme “Smart Forest“, en référence à l’algorithme “Random Forest” de machine learning. Nous y verrons comment on peut écrire des arbres de décision manuellement, et quels avantages/inconvénients cette approche peut avoir par rapport à son cousin Random Forest.