Pour mener à bien le backtest de sa stratégie sous MetaTrader, de nombreuses choses sont à prendre en compte, dont on prend conscience généralement progressivement, après avoir fait des erreurs.
Je vais vous parler ici de ce que j’ai appelé l’effet “glissement”.
Il s’agit d’un effet insidieux dont on peut facilement oublier de tenir compte lors des simulations réalisées.
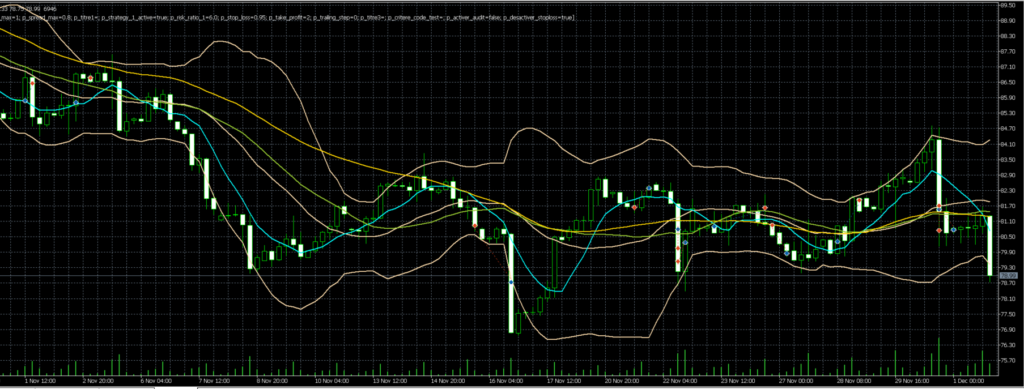
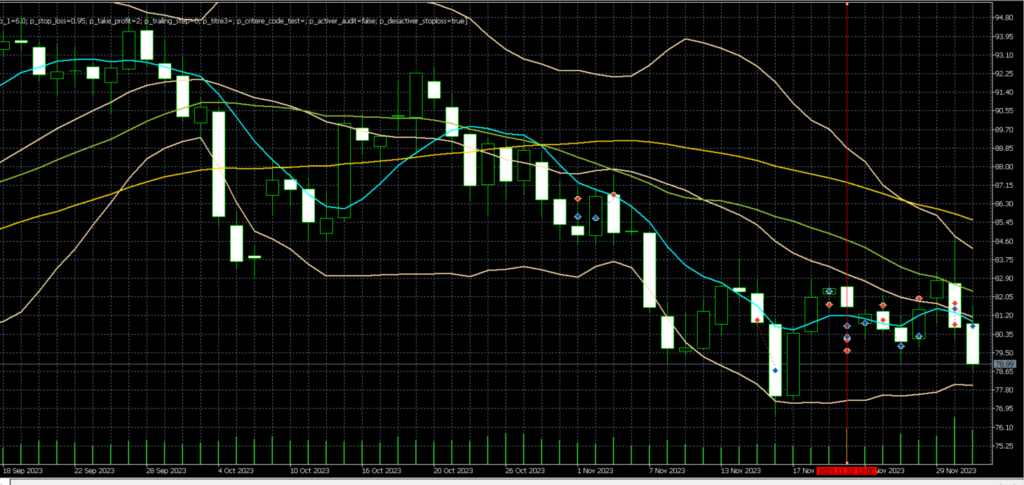
Généralement, une stratégie d’émission de signaux de trading va tenir compte des positions ouvertes. Cela est indispensable pour ne pas générer un trade par minute… Ainsi donc, on émet un trade, et tant que ce trade est ouvert, la stratégie peut être de ne pas ouvrir d’autre trade dans la même direction, ou dans les 2 directions, ou encore elle peut autoriser un autre trade mais à condition qu’il y ait 2h d’intervalle, etc…, etc… Une grande variété de possibilités, mais ces choix doivent être pris tôt dans la conception de notre robot.
Ce dont il faut bien avoir conscience, c’est que par la suite, à chaque modification de l’algorithme, les cartes vont être remélangées, et il va alors être nécessaire de réévaluer la situation.
Par exemple, si vous avez des critères avec des seuils permettant de quantifier un gradient de moyenne mobile, ou un éloignement à un support clé, votre trade sera peut-être bloqué au moment T1, mais sera autorisé un peu plus tard, quand la situation du marché aura légèrement évolué, disons au moment T2.
Ce nouveau trade au moment T2 n’était pas visible auparavant. Il s’agit donc d’un nouveau trade, qui peut-être gagnant, ou perdant.
Si vous avez opté pour la rédaction manuelle d’arbres de décision, cet état de fait peut-être pris en considération en relançant régulièrement les simulations sur la période complète, ceci plusieurs fois lors de la rédaction d’un arbre de décision, et SURTOUT, entre chaque arbre de décision.
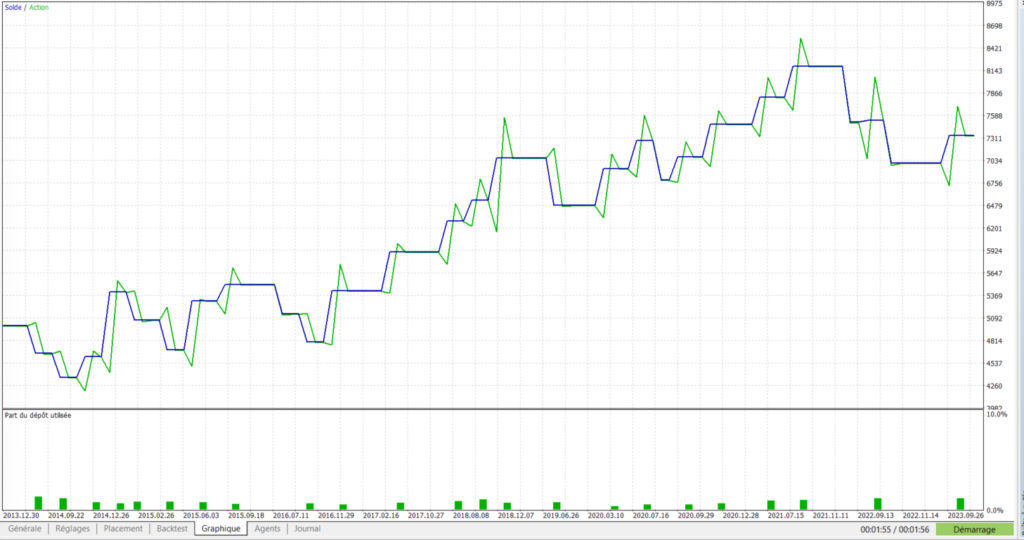
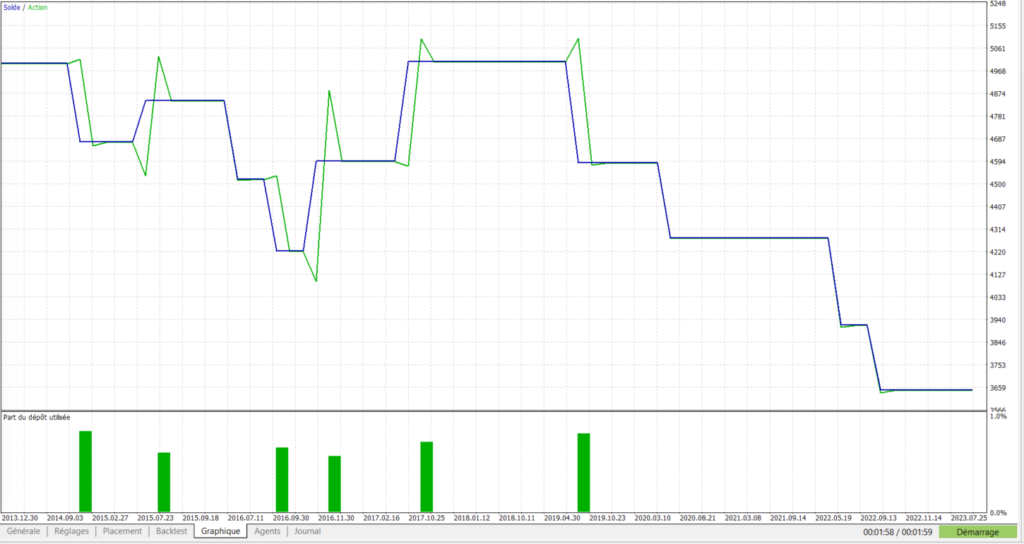
Quelle que soit votre approche dans la conception de votre robot, la clé est donc d’être en mesure de lancer des simulations très régulièrement, à chaque fois que vos modifications ont été en mesure de modifier le paysage de vos trades. Sans cela, vous allez travailler sur la base d’informations erronées et perdre potentiellement des heures de travail.
Pour cela, il faut donc en premier lieu se préoccuper de la rapidité d’exécution des simulations. Une simulation sur 10 années ne devrait pas prendre plus de 30secondes à 1 minute afin de ne pas pénaliser votre travail de développement.
Vous trouverez dans cet autre article des astuces pour accélérer vos simulations si vous en avez besoin.
Une toute autre approche est possible pour répondre à cette problématique.
On peut définir un mode “backtesting” configurable au lancement du robot. Dans ce mode, la stratégie ne limitera plus le nombre de trades émis simultanément, mais imposera une autre règle, par exemple 1 seul trade par bougie H1 ou M30 (fonction de votre stratégie bien sûr). Etant donné que le robot va alors générer plusieurs trades à la fois, il faudra adapter la taille des lots ou le montant du capital afin que tous les trades requis puissent être ouverts.
Il est alors possible d’examiner d’emblée toutes les configurations possibles pour l’entraînement de notre modèle.
Les résultats généraux de la simulation obtenus dans ce mode “backtesting” ne seront bien évidemment pas représentatifs de la réalité. Une fois l’analyse voulue des trades réalisée, il faudra refaire une simulation en mode “normal” afin d’obtenir des chiffres plus réalistes.
Bien sûr ces recommandations sont tout autant valables pour un modèle en machine learning.