Nous allons voir ici comment créer un arbre de décision manuellement. Je ne vais pas rentrer dans le code Metatrader, car chaque développeur a ses propres habitudes, mais m’intéresser plutôt à la philosophie derrière.
Cet article est un complément à la page dédiée à mon algorithme “Smart Forest” que je vous conseille de lire en premier lieu sinon vous risquez d’être un peu perdu.
Tout d’abord, il est indispensable de savoir générer un fichier .csv contenant les trades émis avec toutes les caractéristiques correspondantes au moment de l’ouverture de la position, ainsi que le bilan final du trade, à savoir si il est gagnant ou pas, et aussi dans quelle mesure. Il peut en effet s’agir d’un trade avec un gain important, ou bien un gain minime. Les décisions que l’on prendra par la suite dépendront de ces informations, car nous serons plus à même de sacrifier un petit trade qu’un gros.
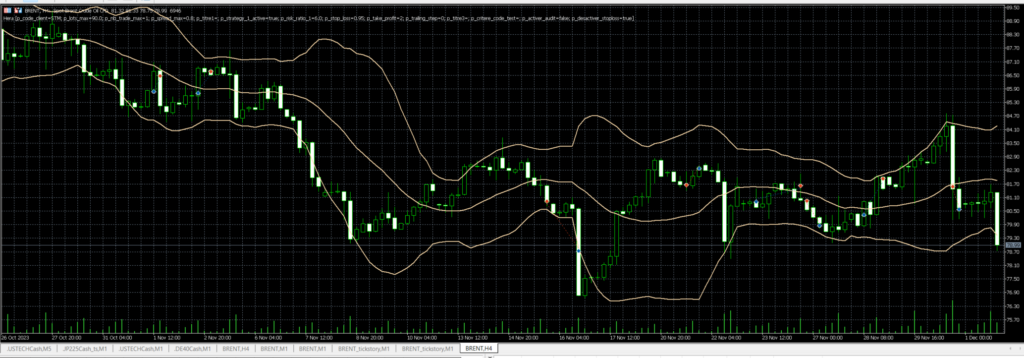
Prenons un exemple récent, le bilan sur novembre de Hera sur le BRENT. Un gain appréciable de 759EUR pour un capital de 5000EUR, mais en y regardant de plus près, sur les 11 trades émis, 4 étaient perdants.
Graphique H4:
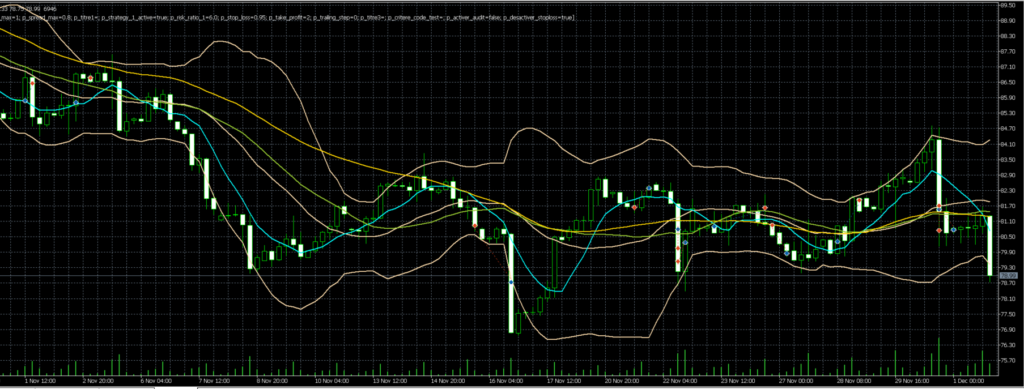
Graphique D1:
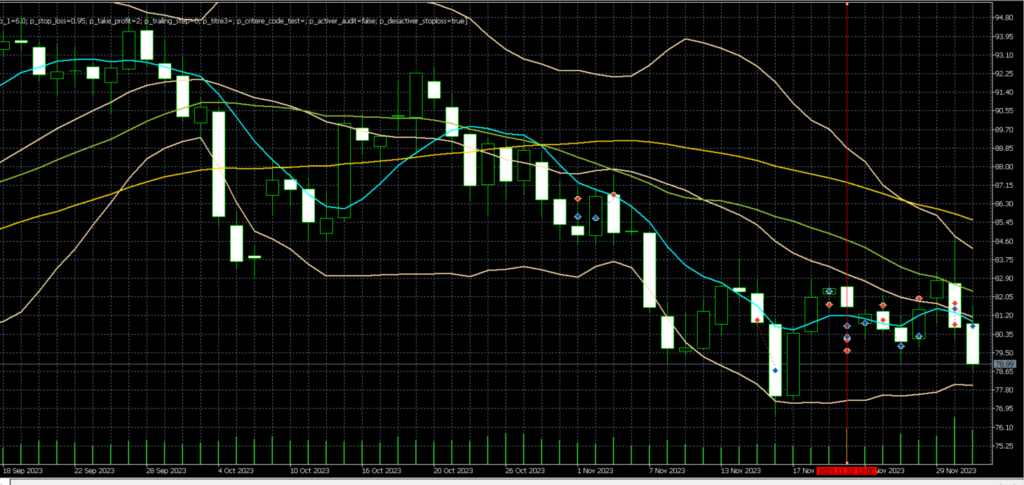
2 de ces trades perdants ont été émis le 22/11/23, sur une très forte bougie h4 baissière, avec des ouvertures de position visiblement très éloignés de la MM8.h4 (en bleu). En daily, on visualise également très bien le fait que ces trades étaient mal positionnés. Il est probable qu’un humain avisé n’aurait pas ouvert de trades à la vente à ce moment là. Le trade perdant du 30/11 semble correspondre au même schéma en H4, nous pouvons donc espérer écrire un arbre de décision qui engloberait ces 3 trades.
Des contrôles qui fonctionnent généralement bien consistent à mesurer les écarts aux moyennes mobiles, ainsi que leurs gradients, ceci souvent en conjonction avec d’autres observations. Parfois il est nécessaire de tester plusieurs variantes afin de trouver ce qui correspond le mieux.
L’observation permet donc d’émettre les premières hypothèses, puis une simulation sur la période globale de test doit être lancée afin d’identifier tous les trades impactés. Chaque hypothèse doit être testée pour être validée.
Dans ce cas, je remarque qu’en H4, les moyennes mobiles ne sont pas « rangées » dans le bon ordre, et le trade est lancé totalement à l’opposé. La MM50 est représentée en jaune, et la MM26 en vert. On a donc la MM8 > MM50 > MM26, ce qui n’est pas une configuration « propre », illustrant un mouvement récent fort dans le sens de l’achat. L’émission d’un trade à la vente, de surcroît mal positionné par rapport aux moyennes mobiles semble effectivement être un mauvais choix, aux probabilités de succès réduites.
Nous allons dans un premier temps émettre des critères les plus généraux possibles, puis ce sont les résultats de la simulation qui nous permettront d’affiner les choses.
On pourrait ainsi écrire pour la vente (ce sera l’inverse pour les achats):
mm8.h4 > mm50.h4
&& mm50.h4 > mm26.h4
&& Bid() < mm26.h4
Ce premier jet nous permet d’isoler 27 trades sur la période de 10 ans (sans nos trades de novembre), ce qui peut sembler faible mais toutefois suffisant pour pouvoir identifier des critères supplémentaires. On peut ajouter à cela nos 3 trades de novembre 2023 qui correspondent également à ce descriptif.
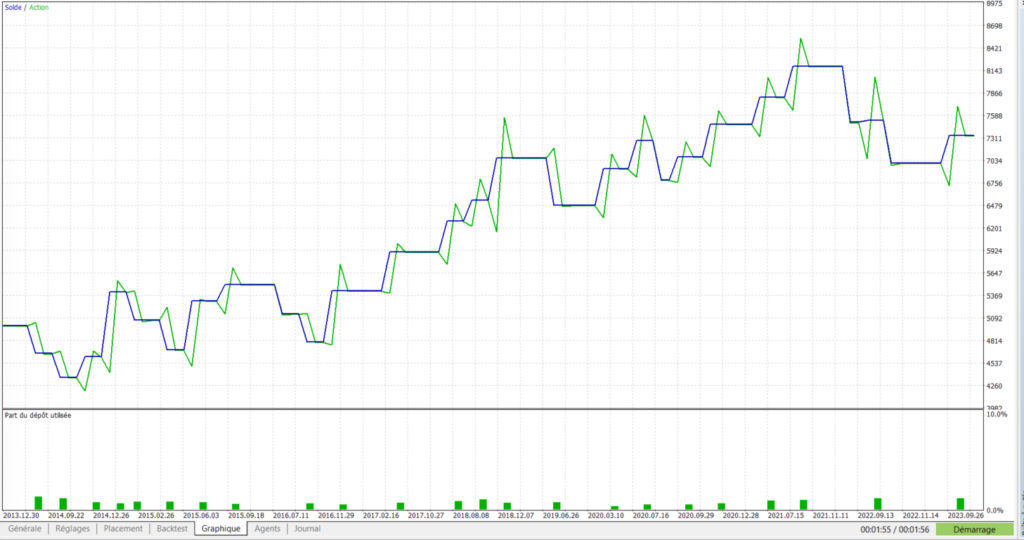
Cela constituera un arbre de taille assez réduite, mais nous pourrons toujours apprécier dans le futur que des trades ne soient plus émis dans une situation comparable. Hera est un robot déjà bien avancé en terme d’optimisation, donc à ce stade, il est normal que les trades gagnants soient majoritaires.
Pour ne pas perdre trop de trades positifs, nous allons voir si il est possible d’affiner un peu les choses. Même si il ne faut jamais s’obstiner à essayer de trouver une cohérence là où il n’y en a pas!
C’est là que le fichier .csv est indispensable.
Avec l’expérience, on peut identifier rapidement les valeurs caractéristiques extrêmes qui permettent de préciser les choses, le but étant de relier entre eux le plus de trades perdants, en excluant au maximum les trades positifs. La lecture des données conjuguée à la visualisation des trades sur la courbe, rend cette technique particulièrement efficace.
Dans cet exemple, les critères supplémentaires conservés vont être relatifs au positionnement du prix vis à vis de la mm8.mn1, de la mm4.mn1, et des gradients de moyenne mobile mm4.d1 et mm8.w1. Il serait quasiment impossible d’identifier ces informations avec leur seuil sans l’aide d’un reporting adapté.
Dans cet exemple relativement simple, la seule lecture du fichier de reporting s’est avérée suffisante, mais le plus souvent, il est nécessaire de recourir à des patterns graphiques pour parvenir à affiner les choses.
On pourrait ainsi écrire, toujours pour les ventes (les seuils sont ici à titre indicatif, ils doivent être déterminés sur des valeurs normalisées et apparaissent souvent très utiles pour quantifier la force d’une tendance ou l’importance d’un éloignement):
mm8.h4 > mm50.h4
&& mm50.h4 > mm26.h4
&& Bid() < mm26.h4
&& Bid() < mm8.mn1
&& Bid() < mm4.mn1 + 500
&& gradient(mm4.d1) < 5
&& gradient(mm8.w1) < 30
Ces nouveaux critères permettent d’identifier désormais les trades suivants (auxquels il faut toujours rajouter nos 3 trades perdants de novembre – s’agissant de jeux de données différents, historique tickstory vs historique récent metatrader, il n’est pas possible de les avoir sur un même graphique. La « fusion » des données doit se faire manuellement).
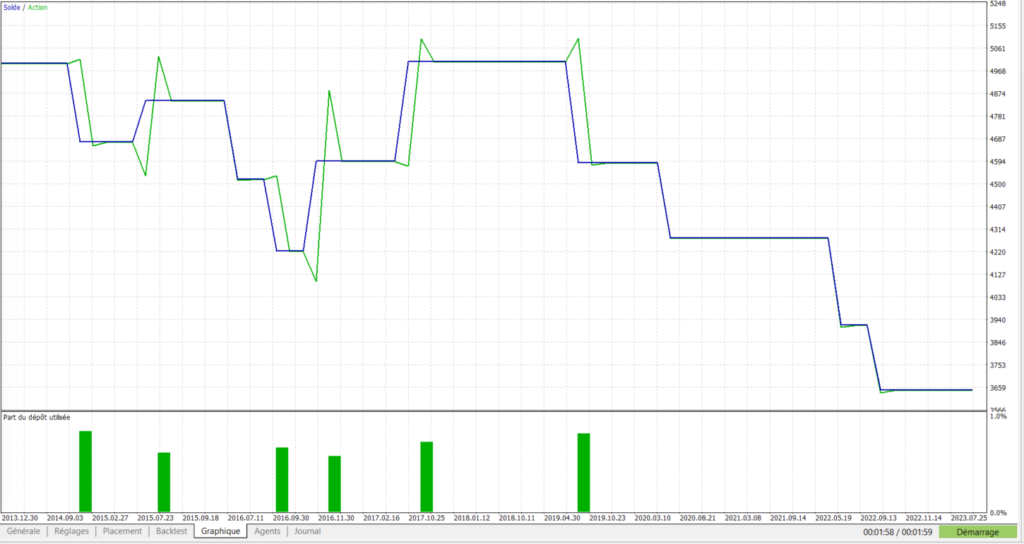
Nous avons conservé ainsi 10 trades (+ 3 trades de novembre), dont seulement 3 gagnants, qui seront désormais exclus par cet arbre de décision.
Les trades sur novembre suite à validation de cet arbre de décision sont ainsi plus « propres » qu’initialement. Il ne reste plus qu’un trade négatif, le 21/11 à 12h00, qu’il serait difficile de sécuriser. Un exemple de trade perdant « par malchance » sur lequel baser un arbre de décision ne semble pas être une bonne idée. S’acharner à vouloir exclure des trades perdants qui sont en toute objectivité bien placés nous ferait tomber dans l’écueil de l’over fitting.
Notre arbre de décision est ainsi achevé, d’une manière assez simple, puisqu’il n’a pas été nécessaire de lui associer des branches.
Quelques mots concernant les branches. Une branche est l’équivalent d’un « sauf si…. », et permet d’exclure d’un arbre de décision un ensemble de trades correspondant à une situation précise. Une branche, qui sera un ensemble de conditions favorables, va donc permettre l’exclusion de trades gagnants d’un arbre de décision.