Cela fait longtemps que je n’ai pas écris pour partager l’avancée de mes recherches, beaucoup de travail en parallèle en plus de mes robots, acquisition d’un grand terrain pour en faire une forêt comestible, et bien sûr tout le quotidien à gérer. Trouver le temps pour l’écriture n’est pas simple dans ce contexte, mais je pense qu’un bilan s’impose.
A l’heure de l’IA, j’ai moi même suivi une formation intensive de 9 mois en machine learning (python) afin d’y voir plus clair et d’être en mesure d’évaluer les apports de ces technologies dans le domaine du trading algorithmique.
Dans tout processus de décision, il est important de prendre en considération tous les éléments: techniques, financiers, contextuels, temps de formation/d’apprentissage/montée en compétence, affinité personnelle, etc…
Il est évident qu’un hedge fund avec des moyens financiers énormes et toute une équipe d’ingénieurs/analystes de haut niveau n’aura pas les mêmes contraintes qu’une mère de famille travaillant seule depuis chez elle 🙂 Les 2 pourront donc très probablement être amenés à faire des choix différents pour la résolution d’un même problème, sans que cela signifie que l’un des deux ait forcément tort.
L’objectif que je me suis fixé il y a quelques années était donc de développer une méthode et des outils simples, impliquant peu de ressources informatiques, s’appuyant sur des logiciels/plateformes gratuits, et permettant de développer assez rapidement des robots de trading performants. Une méthode accessible au plus grand nombre donc, ce que l’IA ne permet pas à mon avis.
L’idée était de remplacer les algorithmes de machine Learning et la puissance de calcul qu’ils nécessitent par de l’intelligence humaine et du bon sens.

Pour illustrer mon propos, je citerai l’exemple donné par un expert en IA (dont j’ai oublié le nom et je m’en excuse), qui précisait que pour entraîner un algorithme à la reconnaissance de chats, il fallait lui fournir des centaines de milliers d’images. A contrario, sa filleule de 4 ans avait développé cette capacité en quelques instants quand on lui avait montré une seule photo de chat…
J’ajouterai à cela la problématique des biais sur les données qui n’est pas à prendre à la légère. Par exemple, si l’on souhaite qu’un algorithme apprenne à faire la différence entre un chien et un loup, on va lui montrer évidemment des photos de chien et de loups que l’on va étiqueter “chien” ou “loup”. Mais si tous nos chiens portent un collier ou sont couchés sur un canapé, l’algorithme prendra cela comme étant une caractéristique déterminante alors que cela n’est pas le cas. Un humain le comprend d’emblée intuitivement, alors que l’algorithme n’en sait rien. En matière de trading, il est important de comprendre comment ces algorithmes de machine learning fonctionnent, pour ne pas se faire duper et leur prêter une intelligence qu’ils n’ont pas forcément. Il n’y a qu’en comprenant leur fonctionnement, leurs points forts et leurs faiblesses, que l’on peut espérer en tirer le meilleur parti. Mais si on ne leur mâche pas correctement le travail, il est clair que le résultat ne sera pas à la hauteur de nos efforts et de nos espérances.
Un autre point important concerne les jeux de données à leur fournir. Est-ce que 10 années suffisent? j’en doute. Hors en pratique il est difficile d’avoir accès à des jeux de données précis et gratuits qui soient supérieurs à 10 ans. On peut envisager de fusionner plusieurs jeux de données, par exemple en prenant plusieurs actifs différents mais proches en émettant l’hypothèse qu’ils réagissent de manière identique. On peut aussi prendre des jeux de données d’un même actif mais de brokers différents, ou en modifiant les heures. Des parades sont possibles, mais seraient elles suffisantes? Question très difficile à répondre car cela nécessite de faire de nombreux essais, et donc beaucoup de temps de R&D.
L’autre point crucial lié aux biais est qu’il ne faut pas oublier que des trades peuvent être perdants tout en étant bien positionnés et parfaitement exécutés (on n’est jamais à l’abri d’un mouvement brutal instantané avant que le cours ne revienne à la normale). Ces trades perdants par manque de chance ne devraient pas être pris en considération par les algorithmes. De même que les trades gagnants “par chance”.
Mon propos n’est pas de dire que l’IA n’est pas adapté au trading, car ce n’est pas du tout ce que je pense, mais plutôt de dire que c’est loin d’être une solution abordable et facile d’utilisation comme quelques influenceurs aiment à le laisser croire. Les pièges sont nombreux et il faut avoir les moyens humains, financiers, et temporels pour espérer les solutionner.
Suroptimisation/Sous-optimisation
Par peur de la suroptimisation, beaucoup ont renoncé à l’idée d’optimiser leur algorithme, et recherchent donc un “alpha”, c’est à dire un signal le plus simple possible (certains se fixent des limites sur le nombre de critères à 4 ou 5), qui seraient globalement gagnant. Par peur de la suroptimisation, ils sont alors dans de la sous-optimisation. Est-ce mieux? j’en doute. Cette quête d’une formule magique simple pouvant résoudre un problème d’une telle complexité me semble comparable à la recherche d’une aiguille dans une botte de foin. Je ne dis pas que c’est impossible, je n’aurais pas cette prétention, mais je suis sûre que c’est une tâche très complexe, chronophage et aux résultats très aléatoires. C’est pour cette raison que j’ai préféré me concentrer sur la recherche d’une méthodologie qui une fois au point, pourrait permettre de manière certaine d’obtenir un robot prometteur en un laps de temps déterminé. “Prometteur” dans le sens “digne ‘intérêt”.
La suroptimisation est un réel problème, car il faut bien comprendre que l’on peut très facilement développer un algorithme avec un facteur de profit énorme, testé sur 10 ans, et pourtant, une fois sur des données temps réel, donnera des résultats catastrophiques. Et je sais de quoi je parle 😀
Si vous souhaitez acquérir un robot de trading, demandez toujours à avoir des historiques temps réel ou bien une période d’essai. Les résultats d’une simulation n’ont aucune valeur malheureusement.
Malgré ces risques de suroptimisation, je suis restée convaincue que l’optimisation était une voie prometteuse. C’est juste qu’il faut prendre le temps, apprendre de ses erreurs, et tenter de comprendre comment écrire des critères à la fois efficaces et robustes.
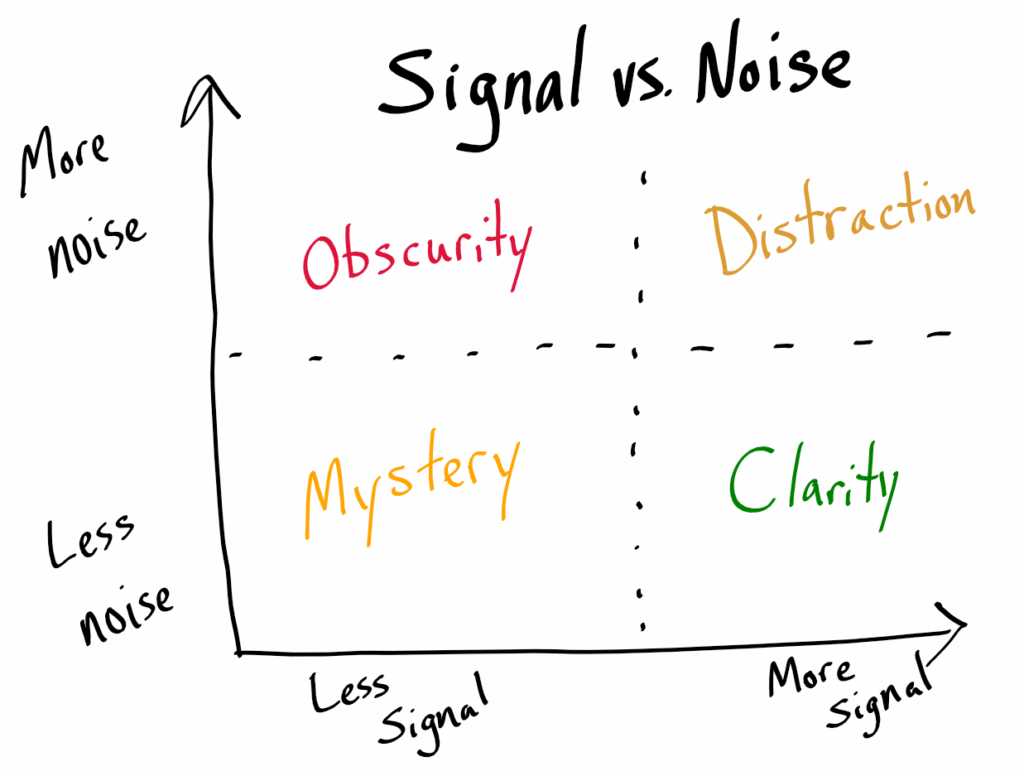
Il faut par exemple bien comprendre ce qu’est la notion de “bruit” en trading. On pourrait dire que le bruit correspond aux mouvements spontanés qui apparaissent sur les petites échelles de temps et qui sont très difficiles à prédire car quasiment erratiques. Au-dessus de ce bruit, on va trouver des tendances plus faciles à identifier et donc à suivre. On va identifier aussi des patterns reproductibles, l’analyse technique pouvant être très précieuse à ce niveau. On peut comprendre intuitivement qu’écrire des critères qui sont situés dans la zone de bruit peut-être très dangereux. De la même manière, il faut être en mesure d’estimer la largeur moyenne de la bande de bruit afin de pouvoir positionner notre SL au-delà, avec une marge de sécurité. Sinon on peut être certain que même la meilleure optimisation ne pourra pas empêcher les déclenchements intempestifs et inappropriés du SL. Donc si l’on cherche à optimiser un robot de trading => il faut impérativement se mettre hors de la zone de bruit.
Pour parler un peu plus concrètement, avec les années d’expérience désormais derrière moi, et sans compter les nombreuses années qui vont suivre!, j’arrive désormais à produire 1 robot par mois, en travaillant dessus partiellement les soirs et week-end. Je travaille sur un PC ce qu’il y a de plus normal, avec des logiciels gratuits ou presque (metatrader, et Excell). Sur ma dernière génération de robots, j’ai pu augmenter le nombre de trades d’étude de manière très significative puisque je pars d’un nombre de trades dépassant les 60000 (j’étais au préalable plutôt en dessous de 10000). Sur cette base de trades, je recherche les patterns à haut risque afin de les exclure. J’écris ainsi manuellement des “arbres de décision” qui me permettent d’exclure progressivement des configurations de marché, et sur ces 60000 trades, je vais finalement en garder 10000 environ, ce qui va représenter tout de même 1000 trades par année environ, ce qui reste très intéressant. Ces 10000 trades restants correspondent donc aux configuration de marché qui, statistiquement parlant, pour les TP/SL déterminés, ont la plus forte probabilité de succès.
Avec l’expérience, cette méthode vous permet de coder votre robot avec une bonne série Netflix en tâche de fond 🙂
Autre point intéressant, le signal d’entrée n’a plus vraiment d’importance. Au contraire, on cherche à avoir un grand nombre de trades afin de “scanner” le marché de la façon la plus précise possible. Tout signal d’entrée applique une restriction drastique du nombre de trades et nous fait rentrer dans l’étude d’un cas particulier. Et comme dit plus haut, moins il y a de trades à analyser, moins robustes seront nos arbres de décision.
Théoriquement, on pourrait se passer complètement de signal d’entrée, et je pense que je vais progressivement tendre vers cela d’ailleurs. La seule difficulté est humaine: comment arriver à analyser, humainement, des centaines de milliers de trades? Il y a bien évidemment un seuil au-delà duquel il devient indispensable d’avoir recourt à des algorithmes d’analyse pour mâcher le travail, des algorithmes qui arriveraient à prendre le meilleur de l’humain et le meilleur de l’IA pour les faire travailler ensemble. Réflexion en cours!
Mais je pense que jusqu’à 200.000 trades, l’analyse peut encore se faire sur Excell, à condition d’avoir quelques années d’expérience derrière soi.
Sur la base de mon expérience passée, je dirais qu’il faut écrire généralement une centaine d’arbres de décision pour arriver à faire un tour assez complet des différentes situations de marché. Mais rien n’empêche d’aller au-delà. Ces critères vont bien entendu utiliser plusieurs échelles de temps, et principalement les plus élevées: monthly, weekly, dayly, h12, parfois h4/h2/h1 si requis mais modérément car on rentre progressivement dans la zone de bruit. Ces critères vont souvent rechercher les valeurs de certains indicateurs combinés avec le positionnement . Par exemple, à la vente, le RSI weekly a atteint la limite des 30, la mm 2 en dayly est défavorable et indique un retournement et de plus le cours est situé en dessous de la mm2. On peut regarder des croisements de moyenne mobile, de stochastique, de macd, des pentes de mm très défavorables, etc…. tout est envisageable, à condition de rester en dehors de la zone de bruit, de penser à normaliser ses mesures, et de rester le plus généraliste possible. Le fait de disposer d’un grand nombre de trades va permettre d’en “sacrifier” beaucoup, de rester généraliste, et donc de limiter la suroptimisation.
L’autre question qui fâche est : “comment savoir si un algorithme de trading est rentable ou non?“. Pendant mes longues études ainsi que durant ma vie professionnelle en tant qu’ingénieur, j’ai toujours appris que : “ça marche” ou “ça ne marche pas”. Quand vous développez une application, vous vous rendez très vite compte si cela fonctionne ou non, surtout si une magnifique erreur 500 apparaît sur votre navigateur. C’est clair, rapide et sans discussion possible.
Mais en trading… c’est une toute autre histoire. Bienvenu dans le monde merveilleux de la probabilité! Ce robot est-il rentable? Probablement 😀 Au mieux pourra-t-on dire qu’il a été rentable les 6 derniers mois mais comme les performances passées ne présument en rien des performances à venir… on est bien avancé là.. J’ai ainsi eu des cas de robots avec des performances incroyables en temps réel pendant plusieurs mois, puis les performances s’inversent et ne remontent pas. Ou inversement, des robots qui ont eu des départs décourageants, puis se sont mis à performer. Il est très difficile d’y voir clair dans ces conditions.
De plus, quand on lance une simulation sur 10 ans, cela prend quelques secondes ou minutes, donc on peut avoir une vision globale instantanément. Mais dans la vraie vie, 10 ans, cela prend 10 ans…
Une question primordiale à se poser est donc: “quelle est la durée minimale d’exécution en temps réel qui va me permettre d’évaluer les performances d’un robot?”. 6 mois, 1 an, 2 ans? Vous le comprenez maintenant, parmi les qualités indispensables d’un algo-trader, on trouvera la patience et la persévérance! Pour ma part, je considère désormais qu’il faille un minimum de 1 année. Bien sûr, sur les nombreux robots “prometteurs” tous ne valideront pas leurs performances sur la durée. D’où l’intérêt d’avoir une méthodologie efficace permettant de développer des robots régulièrement. Méthodologie qui s’améliorera toujours au fil du temps. On augmente ainsi nos chances d’obtenir LE robot ultime, celui dont les performances sont régulières dans le temps et dans lequel vous avez suffisamment confiance pour lui confier de gros capitaux.
Se lancer dans l’algo trading et espérer aboutir à des résultats concrets en quelques mois peut être source de grandes désillusions, surtout si vous partez sans formation/accompagnement adapté qui vous ferait gagner certainement plusieurs années. Si on m’avait appris dès le départ tout ce que je sais maintenant par la force de l’expérience, j’estime que j’aurais gagné 3 années d’efforts…
Quelques mots maintenant pour dire où j’en suis de mes recherches.
Je dois avoir une bonne dizaine de robots que je suis de près et qui me semblent prometteurs, avec des résultats encourageants depuis plusieurs mois. Nasdaq, DJ30, Gold, BTCUSD, plusieurs paires Forex. Désormais, la grande majorité des robots sortis sont prometteurs, ce qui représente une réelle avancée par rapport à il y a 1 an et me conforte dans le fait que je suis dans la bonne direction. Par “prometteur” j’entends que les performances obtenues sur les premiers mois sont assez proches des performances sur période d’optimisation. Mais pour l’instant le cap des 1 an n’a pas encore été franchi. Prudence et patience sont de mise comme toujours!

A titre d’exemple, ci-dessus les résultats obtenus pour les 2 premières semaines d’exécution du dernier né “Phoenix_XAUUSD”, avec un beau score de 12% conforme aux résultats de simulation. La stratégie utilisée consiste à prendre un SL 10 fois supérieur au TP. Le % de trades gagnants doit normalement dépasser les 90%, ce qui rend cohérent le doublement de la taille des positions pour les trades consécutifs à une perte. Ainsi, bien que l’on ait un SL 10 fois supérieur au TP, seuls 5 trades sont nécessaires pour récupérer une perte. Stratégie qui fonctionne très bien dans la majorité des situations, mais bien évidemment, il reste possible que 2 pertes voire plus s’enchaînent. Il faut toujours garder à l’esprit que ces situations peuvent se produire et donc rester modeste sur le choix des tailles de positions initiales. Toujours dimensionner ses trades par rapport au risque pris et non aux gains espérés même si c’est très tentant! La fréquence des trades obtenue ici (en moyenne 3 trades/jour) permet d’augmenter les performances mais aussi de se rendre compte plus rapidement des performances réelles du robot. Si l’on s’attend à + de 90% de trades gagnants et qu’il enchaîne les pertes, c’est à coup sûr que quelque chose ne va pas et il ne sera pas nécessaire d’attendre 6 mois pour s’en rendre compte. Mais comme toujours, 2 semaines de résultats ne veulent pas dire grand chose. Un robot qui monte vite peut descendre bien plus vite encore, il ne faut jamais l’oublier. D’où l’importance de prendre son temps avant de passer sur de l’argent réel.
Ayant désormais un nombre important de robots en test et sous étroite surveillance, parmi lesquels j’ai espoir de voir émerger quelques champions (il est important de rêver !), je vais maintenant me pencher beaucoup plus sérieusement sur les modes d’exécution via Metatrader, car je me suis laissée un peu débordée par mes élans créateurs… Faire tourner en temps réel autant de robots n’est pas aussi simple qu’il n’y paraît car de toute évidence, Metatrader gère très mal cela… (beaucoup de trades ne sont pas pris lorsque plusieurs robots tournent sur un même Metatrader ), et l’espace disque requis est devenu important. Bref, ce point sera ma priorité pour la rentrée 2025, date à laquelle j’aurais sûrement plus de temps à consacrer au trading.
J’essaierai d’être plus régulière dans la mise à jour de ce blog. J’espère aussi pouvoir proposer des formations/accompagnements pour transmettre tout ce que j’ai appris. Je crois fermement en la richesse des échanges, et aux bénéfices réciproques!
A très bientôt j’espère!
Stéphanie