L’algorithme “Smart Forest” est le fruit d’un processus personnel de R&D de plusieurs années, adapté à la plateforme MetraTrader5.
Chaque nouveau robot a été l’occasion d’améliorer et d’affiner cette méthodologie pour aboutir à des prédictions de plus en plus fiables et des robots plus robustes.
Au départ, certaines hypothèses sont émises:
- 1/ il est possible d’identifier par un ensemble de critères des configurations de marché reproductibles,
- 2/ pour une configuration de marché donnée, la probabilité de succès/échec d’un trade évaluée par le passé reste valable pour le futur
On suppose donc que les historiques d’évolution des prix d’un actif portent en eux-mêmes les informations nécessaires pour que l’on puisse parvenir à une prédiction correcte des mouvements à venir. Cela constitue les fondements de base de l’analyse technique qui a fait ses preuves depuis plus de 50 ans, ce qui en fait donc des hypothèses très acceptables.
La grande difficulté réside dans l’identification des caractéristiques (features) permettant d’identifier une “configuration de marché” reproductible et l’évaluation de sa probabilité.
L’algorithme “Smart Forest” tire son nom de son cousin “Random Forest” qui est un algorithme bien connu et largement utilisé dans différents domaines, et notamment celui des prédictions de données boursières. Je ne vais pas rentrer ici dans le détail sur le fonctionnement d’un algorithme Random Forest, mais le plus important à retenir ici est qu’il est constitué d’un ensemble d’arbres de décision (decision tree) qui, combinés entre eux, permettent d’augmenter la précision du modèle initial.
Pour constituer un arbre de décision, Random Forest va, comme son nom l’indique, sélectionner des caractéristiques de manière aléatoire afin de tenter d’identifier des patterns intéressants dans l’ensemble des données mises à sa disposition. On est dans le domaine de l’apprentissage automatique, qui a le vent en poupe depuis plusieurs années.
En application aux données boursières, même si le codage peut ne prendre que quelques lignes grâce au merveilleux langage qu’est Python, la mise en œuvre d’un algorithme Random Forest soulève tout de même des difficultés majeures. Il faut en effet fournir à l’algorithme toutes les caractéristiques pertinentes dont il peut avoir besoin pour bien faire son travail. Or nous ne sommes pas dans un simple problème de prédiction de température…. Les marchés boursiers sont d’une complexité rare, ce qui fait dire régulièrement à des experts en machine learning qu’ils doutent même de leur caractère prévisible.
Dans son livre “Advances in Financial Machine Learning”, Marco Lopez de Prado, un expert dans ce domaine, parle dès son introduction des moyens humains et technologiques considérables nécessaires pour faire aboutir un tel projet. Très loin des tutoriels que l’on trouve à foison sur internet et sur YouTube qui laissent penser que c’est simple.
Le choix des caractéristiques à utiliser est l’une des grandes difficultés, et seule l’expérience, les essais et erreurs, peuvent nous permettre de progresser. Indicateurs techniques, rsi, stochastique, bandes de bollinger, moyennes mobiles, gradients de moyennes mobiles, positionnement des moyennes mobiles entre elles, etc, etc… et ceci dans différentes échelles de temps. A cela s’ajoutent l’identification “visuelle” de figures chartistes qui, si elles ne sont pas données à l’algorithme, ne seront pas utilisées. Or ces figures jouent un rôle important puisque les marchés sont le résultat d’un ensemble vaste de facteurs, et la psychologie des traders en fait partie.
Ainsi, parmi les difficultés principales soulevées par la mise en oeuvre d’un algorithme Random Forest pour des données boursières, je donnerai les suivantes:
- difficulté de choisir les caractéristiques les plus pertinentes
- mauvaise interprétabilité
- difficulté d’une labellisation vraiment pertinente. En effet, des trades peuvent être gagnants “par chance” et perdants “par malchance”. Ce serait une erreur de les prendre en compte dans l’élaboration des critères
La mise en œuvre de “Smart Forest” a pour ambition d’essayer de répondre à ces problématiques, en remplaçant l’aléatoire par l’analyse humaine éclairée. Pour cela, une méthodologie très rigoureuse a dû être mise en œuvre, et des solutions trouvées aux nombreuses difficultés rencontrées tout au long du chemin.
Bien entendu, chaque approche a ses points forts et ses points faibles et il est rare de trouver une solution parfaite. Smart Forest ne déroge pas à la règle.
Le remplacement de l’automatique par l’humain, si il résout certains problèmes, va en introduire d’autres: augmentation du risque de bug et des mauvaises décisions qui peuvent induire de l’over-fitting, durée de développement importante quoique raisonnable (il faut compter plusieurs semaines à plusieurs mois pour finaliser l’écriture d’un nombre satisfaisant d’arbres de décision)
Smart Forest: un algorithme sur 2 niveaux
L’algorithme “Smart Forest” est constitué de 2 niveaux principaux:
- Niveau 1: stratégie brute. A ce niveau, une stratégie simple est implémentée, dont l’objectif est de générer suffisamment de trades, avec une proportion de trades gagnants satisfaisante. Les trades doivent être suffisamment représentatifs pour que l’on puisse émettre des statistiques dessus. A ce niveau, c’est le nombre de trades gagnants qui nous intéresse principalement, plutôt que leur proportion.
- Niveau 2: arbres de décision. Ce niveau constitue le véritable cœur du robot. La forêt peut être constituée de 50, 100, voire même plus d’arbres de décisions. Chaque arbre a la responsabilité d’identifier une configuration de marché précise, qui est particulièrement défavorable à notre stratégie. Vous l’aurez certainement compris, c’est ici que nous allons enlever les trades perdants générés par notre stratégie d’entrée. Les arbres peuvent avoir des tailles très différentes et ainsi être composés d’un seul tronc, ou bien d’un tronc et de plusieurs branches. Chaque branche étant chargée de gérer les exceptions. Nous verrons plus bas un exemple pour illustrer ce point.

A cela s’ajoute bien entendu une stratégie de sortie adaptée à notre stratégie d’entrée. Il est important que celle-ci soit déjà bien définie avant d’entamer l’écriture des arbres de décision, notamment la modification des stop loss et take profit peut avoir un impact très important sur les critères retenus. En effet, avec un stop loss serré, les arbres de décision seront beaucoup plus “stricts”. Si l’on augmente après coup le stop loss, de beaux trades gagnants peuvent alors être bloqués. Il s’agit clairement d’un point faible de cette approche manuelle par rapport à ses homologues de Machine Learning, mais quand on en bien conscience, on fait en sorte de faire ses choix correctement dès le départ et de ne pas y revenir dessus après.
Pour qu’un trade soit validé, il doit passer brillamment l’examen auprès de chacun des arbres de décision (application d’un “ET logique”). Donc si on a 50 arbres de décision, correspondant à 50 configurations de marché distinctes, l’algorithme va évaluer pour chacune de ces configurations si le trade en fait partie ou non, et va ainsi lui donner le droit de passage ou pas.
Tous ces arbres de décision sont parfaitement décorrélées, et peuvent être évalués/améliorés indépendamment les uns des autres grâce à des outils adaptés. Le risque d’over-fitting n’est pas tant lié au nombre d’arbres de décisions que l’on va implémenter, mais plutôt à la profondeur maximale autorisée pour ces arbres. Ainsi, plus un arbre va décrire une configuration de marché très spécifique, notamment en descendant dans les échelles de temps, moins il y aura de chances que cette même configuration, avec exactement les mêmes conditions, se rencontrent à nouveau dans le futur. Et c’est exactement ce que l’on veut éviter. On recherche avant toute choses des situations qui se sont passées un nombre suffisant de fois par le passé, avec majoritairement des trades perdants, ce qui peut laisser supposer que dans le futur, si cette situation se rencontre de nouveau, elle donnera probablement les mêmes résultats. A causes identiques, conséquences identiques.
Une des clés du succès réside ainsi dans la capacité à capter les éléments clés permettant l’identification d’une configuration de marché, sans entrer trop dans les détails.
Marco Lopez de Prado utilise une structure assez comparable à celle-ci, mais introduit un concept supplémentaire: chaque arbre retourne non pas “oui” ou “non” mais plutôt la probabilité du trade à être gagnant. En combinant les probabilités de chacun des arbres, il en déduit ensuite la taille de la position la plus adaptée (éventuellement 0).
Si vous souhaitez aller plus loin sur la démarche de création manuelle d’un arbre de décision, cet article vous présente un exemple simple.
Mesure de l’évolution des performances
Nous allons voir maintenant, en application au robot Pegase, comment l’ajout d’arbres de décision va influencer les performances globales de notre modèle.
Contexte: USTECH, sur période 30.12.2013 / 11.11.2023.
Risk ratio per trade: 5%
Capital initial: 5000$
Pegase – USTECH – Evolution du capital avec 0 arbre:
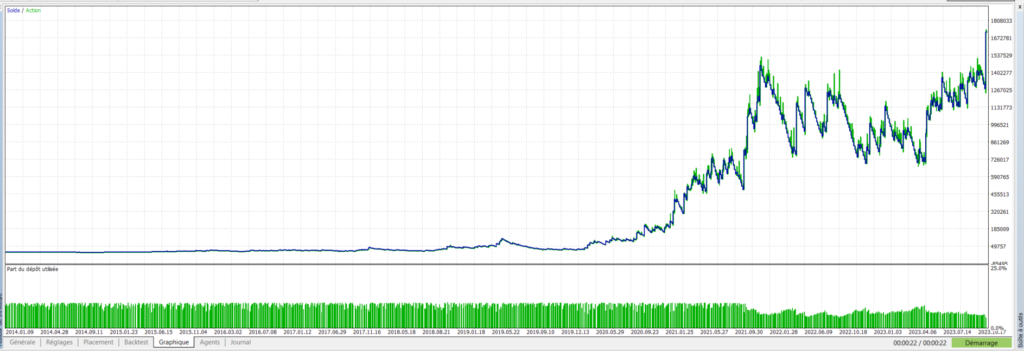
Pegase – USTECH – Evolution du capital avec 10 arbres:
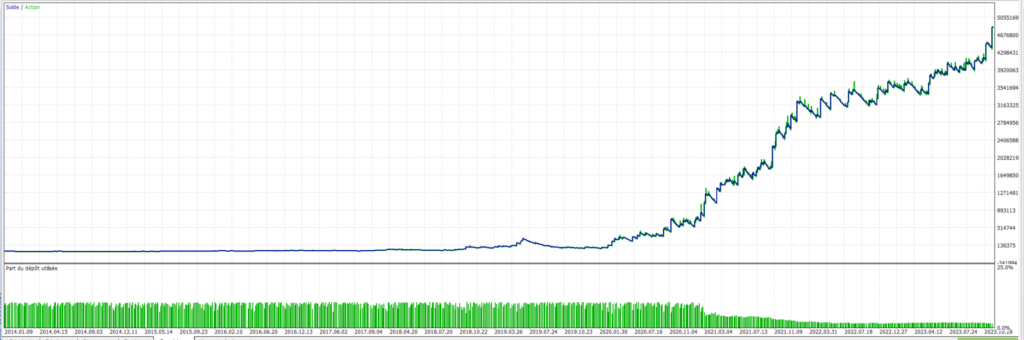
Pegase – USTECH – Evolution du capital avec 20 arbres:
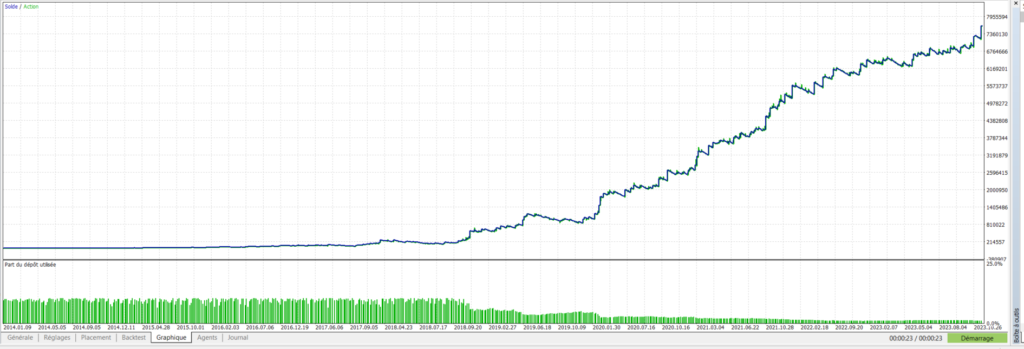
Pegase – USTECH – Evolution du capital avec 50 arbres:
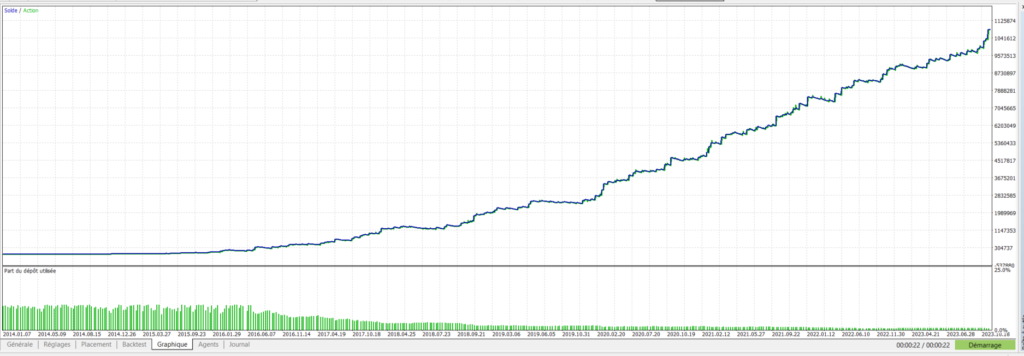
Sous forme de tableau, voici synthétisées les informations parmi les plus intéressantes (risque par trade 5%):
| Nombre d’arbres | Profit total Net ($) | Facteur de profit | WinRate (%) | Nombre de trades | DrawDown max relatif (%) |
|---|---|---|---|---|---|
| 0 | 1 712 621$ | 1,24 | 32,43% | 919 | 82,72% |
| 10 | 4 841 369$ | 1,71 | 34,66% | 802 | 78,05% |
| 20 | 7 636 079$ | 2,11 | 39,01% | 669 | 64,36% |
| 30 | 9 932 294$ | 2,81 | 44,94% | 534 | 48,96% |
| 40 | 10 536 303$ | 3,14 | 47,60% | 500 | 48,96% |
| 50 | 10 818 877$ | 3,35 | 48,72% | 470 | 49,04% |
Bien évidemment, les montants des profits générés ne veulent plus dire grand chose à ces niveaux-là. Si l’on est prêt à risquer 5% sur 5000$ par trade, on y serait bien moins disposé avec un capital de 100.000$. Le risque s’apprécie en fonction du capital à disposition, et ces simulations ne reflètent pas ce point. Les autres informations sont bien plus intéressantes. On constate une évolution nette et rapide du taux de trades gagnants, et du facteur profit. Le nombre de trades a été divisé par près de 2 au bout de 50 arbres, ce qui montre bien que l’approche consistant à enlever les trades perdants (ou faux positifs) est une stratégie payante. Le drawdown quant à lui reste trop élevé à 49% même si il a bien diminué depuis le premier lancement. Toutefois ce chiffre est à relativiser car on a opté ici pour un paramétrage très agressif avec 5% du capital mis en jeu sur chaque trade. Cela dénote toutefois la présence de séries de trades perdants assez importantes, et il y a sûrement des choses à améliorer dans ces zones de marché.
L’effet de “lissage” de la courbe est assez flagrant entre le premier graphe et le graphe obtenu après 50 arbres. Ce lissage peut aussi être interprété comme un défaut puisque l’on rentre dans la catégorie périlleuse du “trop beau pour être vrai”. C’est pour cette raison que l’attente de résultats suffisants sur les données futures sont primordiaux pour une validation/invalidation du modèle.
En machine learning il est d’usage de diviser le jeu de données en 2 parties: une partie pour l’entraînement et une autre partie pour l’évaluation du modèle. La séparation se fait de manière aléatoire, tout en respectant le caractère chronologique des données pour éviter le phénomène de “fuite temporelle”. Concrètement, des fenêtres glissantes peuvent par exemple être utilisées pour répondre à cette spécificité. Une telle implémentation est bien plus complexe à mettre en œuvre dans un environnement Metatrader. On pourrait bien entendu réserver la dernière année pour l’évaluation du modèle, mais cela ferait perdre des informations cruciales. Un historique de 10 années est déjà assez limité, si en plus on enlève une année… A cela il faut ajouter le fait que nous utilisons des tendances weekly et monthly lors de l’écriture des arbres de décisions. Evincer une année complète reviendrait à évincer totalement un contexte de marché probablement unique sur le jeu de données. Il m’a donc semblé plus pertinent d’entraîner le robot sur plusieurs actifs proches, 5 indices dans le cas de Pegase, et de réserver un indice supplémentaire à l’évaluation/contrôle de chaque arbre de décision.
Il est également important de préciser que, dans le cas de Pegase, la stratégie initiale brute, pourtant très simple, est déjà gagnante, du moins sur l’USTECH. Le fait d’enlever majoritairement des trades perdants ne devrait donc en aucun cas mettre en péril cette stratégie qui, de toute façon, était déjà gagnante sans optimisation. L’optimisation n’est là que pour ajouter un confort supplémentaire et par la même occasion permettre l’augmentation de la prise de risque et donc des gains espérés.
Ceci étant dit, même si les gains étaient divisés par 2 ou 3, le modèle resterait tout autant intéressant!
Nous allons maintenant regarder l’impact de ces mêmes arbres, sur le même robot Pegase, mais cette fois appliqué à l’indice DE40.
Nous venons de voir que la stratégie brute était gagnante sans arbre de décision sur l’USTECH, mais ce n’est plus le cas sur le DE40.
Pegase – DE40- Evolution du capital avec 0 arbre:
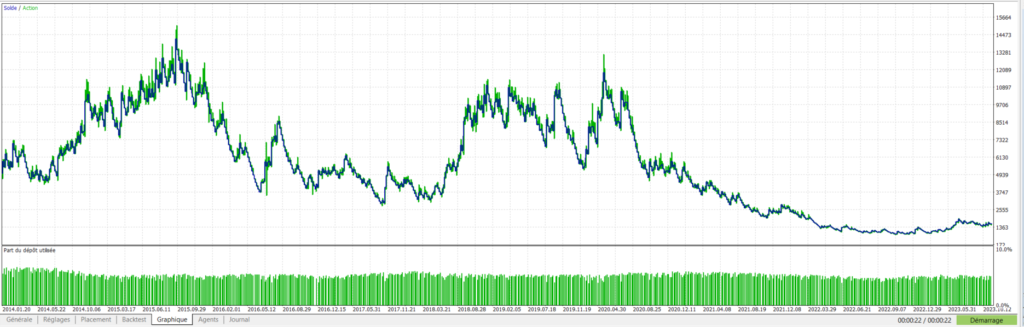
Pegase – DE40- Evolution du capital avec 10 arbres:
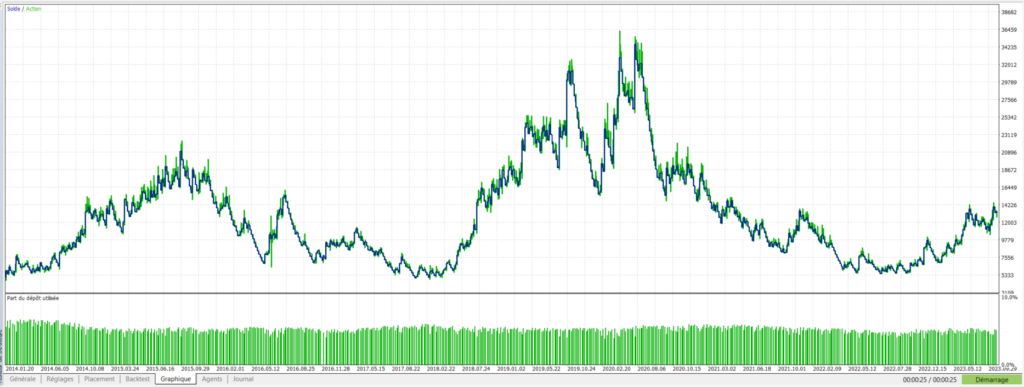
Pegase – DE40- Evolution du capital avec 20 arbres:
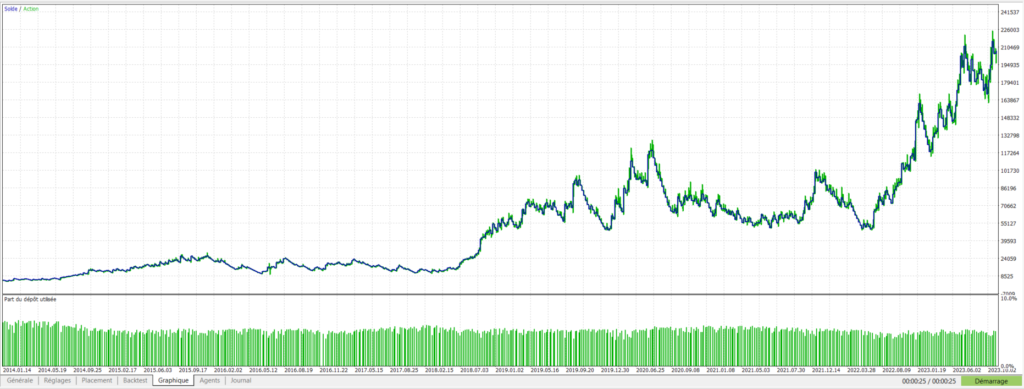
Pegase – DE40- Evolution du capital avec 30 arbres:
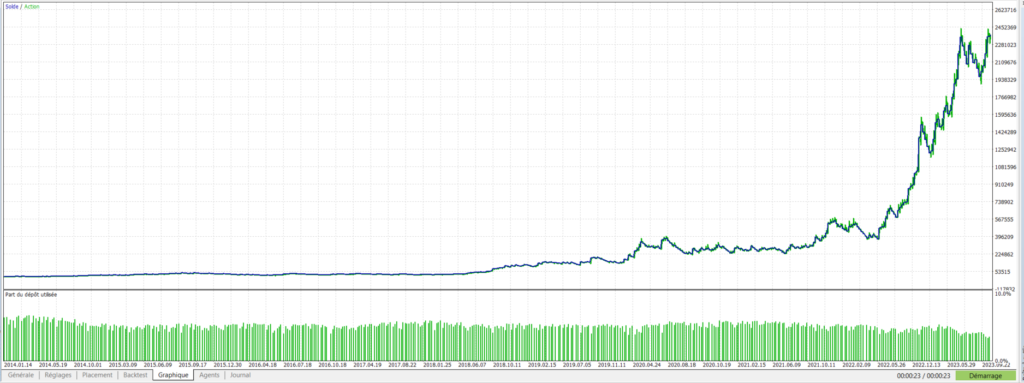
Pegase – DE40- Evolution du capital avec 50 arbres:
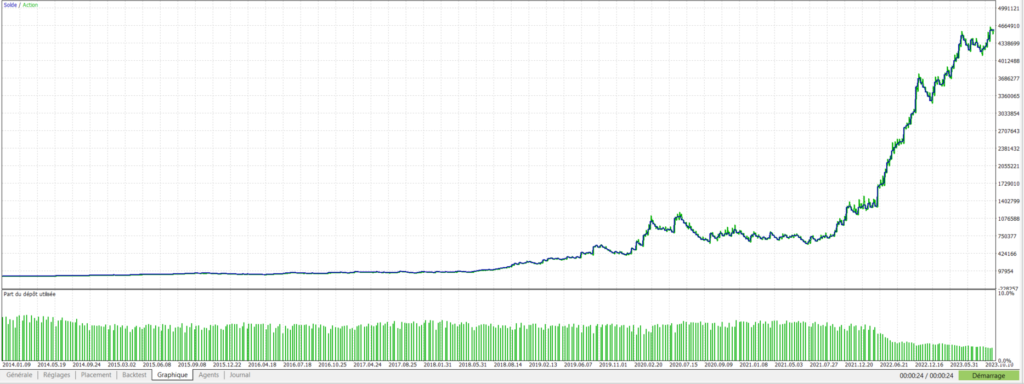
On constate cette fois que nos mêmes arbres de décision ont réussi à faire passer une stratégie de départ perdante en une stratégie largement bénéficiaire.
| Nombre d’arbres | Profit total net ($) | Facteur de profit | WinRate (%) | Nombre de trades | Drawdown max relatif (%) |
|---|---|---|---|---|---|
| 0 | -3 392$ | 0,97 | 43,37% | 731 | 94,16% |
| 10 | 8 395$ | 1,04 | 44,92% | 659 | 84,89% |
| 20 | 202 157$ | 1,26 | 49,04% | 573 | 65,98% |
| 30 | 2 374 225$ | 1,94 | 52,94% | 476 | 68,22% |
| 40 | 3 790 206$ | 2,11 | 53,93% | 458 | 66,57% |
| 50 | 4 588 967$ | 2,15 | 56,63% | 415 | 52,29% |
On peut constater une très nette amélioration globale en terme de proportion de trades gagnants, facteur de profit et drawdown.
Dans les 2 cas (USTECH et DE40), on observe encore des périodes pouvant durer plusieurs mois où les gains stagnent, voire baissent. L’ajout de nouveaux arbres semble nécessaire pour rajouter du confort psychologique à l’utilisateur de ce robot, car c’est un aspect tout aussi important. Faire tourner un robot qui perd de l’argent pendant plusieurs mois est assez décourageant et peut inciter l’utilisateur à cesser de l’utiliser.
C’est la raison pour laquelle je poursuis généralement la création d’arbres de décisions tant qu’il perdure des périodes longues de pertes ou de stagnation. Le risque est bien entendu celui de l’over-fitting, et il est évident que les résultats réels ne pourront pas être aussi linéaires que sur les périodes d’entraînement. Toutefois, il y a over-fitting qui fait passer une stratégie payante à une stratégie perdante, et over-fitting qui va réduire les gains escomptés. La deuxième situation reste acceptable ici étant donné l’ampleur des gains espérés.
Pour conclure …
“Amateurs develop individual strategies, believing that there is such a thing as a magical formula for riches. In contrast, professionals develop methods to mass-produce strategies. The money is not in making a car, it is in making a car factory.
Marcos Lopez de Prado – Advances en Financial Machine Learning
Think like a business. Your goal is to run a research lab like a factory, where true discoveries are not born out of inspiration, but out of methodic hard work. That was the philosophy of physicist Ernest Lawrence, the founder of the first U.S. National Laboratory”
“Smart Forest” est principalement un ensemble de méthodes validées par l’expérience et en perpétuelle amélioration, avec pour objectif la mise en œuvre de robots de trading robustes, tout en limitant l’over-fitting. Quoique relativement complexe, sa mise en œuvre me semble toutefois plus accessible que pour un modèle de machine learning dont il ne faut pas sous estimer la complexité. Son autre avantage est qu’il permet de se familiariser avec les combinaisons de caractéristiques qui “fonctionnent bien”, ce qui sera toujours très utile si l’on souhaite passer à un modèle de machine learning classique.
Si vous souhaitez en savoir plus sur l’algorithme “Smart Forest”, sachez que je propose des formations sur ce sujet. Vous pouvez également me sous-traiter le développement d’un robot de trading correspondant à vos attentes.
J’ai également plusieurs robots en phase d’incubation qui seront probablement mis à disposition par le biais d’abonnements ou à la vente. N’hésitez pas à vous inscrire à la newsletter pour être tenu au courant des informations futures sur ce sujet ou à prendre contact avec moi directement!