Pour mener à bien le backtest de sa stratégie sous MetaTrader, de nombreuses choses sont à prendre en compte, dont on prend conscience généralement progressivement, après avoir fait des erreurs.
Je vais vous parler ici de ce que j’ai appelé l’effet “glissement”.
Il s’agit d’un effet insidieux dont on peut facilement oublier de tenir compte lors des simulations réalisées.
Généralement, une stratégie d’émission de signaux de trading va tenir compte des positions ouvertes. Cela est indispensable pour ne pas générer un trade par minute… Ainsi donc, on émet un trade, et tant que ce trade est ouvert, la stratégie peut être de ne pas ouvrir d’autre trade dans la même direction, ou dans les 2 directions, ou encore elle peut autoriser un autre trade mais à condition qu’il y ait 2h d’intervalle, etc…, etc… Une grande variété de possibilités, mais ces choix doivent être pris tôt dans la conception de notre robot.
Ce dont il faut bien avoir conscience, c’est que par la suite, à chaque modification de l’algorithme, les cartes vont être remélangées, et il va alors être nécessaire de réévaluer la situation. Par exemple, si vous avez des critères avec des seuils permettant de quantifier un gradient de moyenne mobile, ou un éloignement à un support clé, votre trade sera peut-être bloqué au moment T1, mais sera autorisé un peu plus tard, quand la situation du marché aura légèrement évolué, disons au moment T2. Ce nouveau trade au moment T2 n’était pas visible auparavant. Il s’agit donc d’un nouveau trade, qui peut-être gagnant, ou perdant.
Si vous avez opté pour la rédaction manuelle d’arbres de décision, cet état de fait peut-être pris en considération en relançant régulièrement les simulations sur la période complète, ceci plusieurs fois lors de la rédaction d’un arbre de décision, et SURTOUT, entre chaque arbre de décision.
Quelle que soit votre approche dans la conception de votre robot, la clé est donc d’être en mesure de lancer des simulations très régulièrement, à chaque fois que vos modifications ont été en mesure de modifier le paysage de vos trades. Sans cela, vous allez travailler sur la base d’informations erronées et perdre potentiellement des heures de travail.
Pour cela, il faut donc en premier lieu se préoccuper de la rapidité d’exécution des simulations. Une simulation sur 10 années ne devrait pas prendre plus de 30secondes à 1 minute afin de ne pas pénaliser votre travail de développement.
Vous trouverez dans cet autre article des astuces pour accélérer vos simulations si vous en avez besoin.
Une toute autre approche est possible pour répondre à cette problématique.
On peut définir un mode “backtesting” configurable au lancement du robot. Dans ce mode, la stratégie ne limitera plus le nombre de trades émis simultanément, mais imposera une autre règle, par exemple 1 seul trade par bougie H1 ou M30 (fonction de votre stratégie bien sûr). Etant donné que le robot va alors générer plusieurs trades à la fois, il faudra adapter la taille des lots ou le montant du capital afin que tous les trades requis puissent être ouverts.
Il est alors possible d’examiner d’emblée toutes les configurations possibles pour l’entraînement de notre modèle.
Les résultats généraux de la simulation obtenus dans ce mode “backtesting” ne seront bien évidemment pas représentatifs de la réalité. Une fois l’analyse voulue des trades réalisée, il faudra refaire une simulation en mode “normal” afin d’obtenir des chiffres plus réalistes.
Bien sûr ces recommandations sont tout autant valables pour un modèle en machine learning.
Nous allons voir ici comment créer un arbre de décision manuellement. Je ne vais pas rentrer dans le code Metatrader, car chaque développeur a ses propres habitudes, mais m’intéresser plutôt à la philosophie derrière.
Cet article est un complément à la page dédiée à mon algorithme “Smart Forest” que je vous conseille de lire en premier lieu sinon vous risquez d’être un peu perdu.
Tout d’abord, il est indispensable de savoir générer un fichier .csv contenant les trades émis avec toutes les caractéristiques correspondantes au moment de l’ouverture de la position, ainsi que le bilan final du trade, à savoir si il est gagnant ou pas, et aussi dans quelle mesure. Il peut en effet s’agir d’un trade avec un gain important, ou bien un gain minime. Les décisions que l’on prendra par la suite dépendront de ces informations, car nous serons plus à même de sacrifier un petit trade qu’un gros.
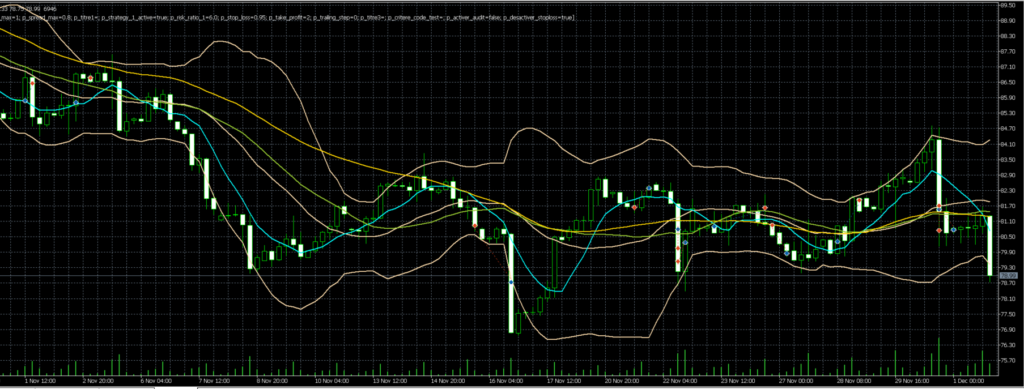
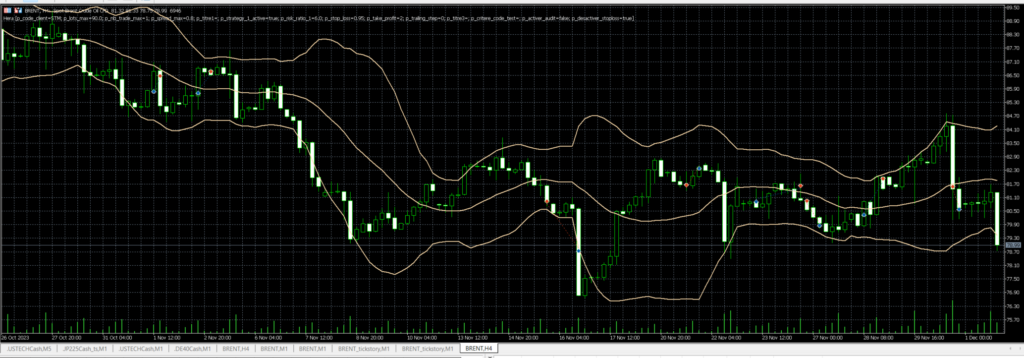
Prenons un exemple récent, le bilan sur novembre de Hera sur le BRENT. Un gain appréciable de 759EUR pour un capital de 5000EUR, mais en y regardant de plus près, sur les 11 trades émis, 4 étaient perdants.
Graphique H4:
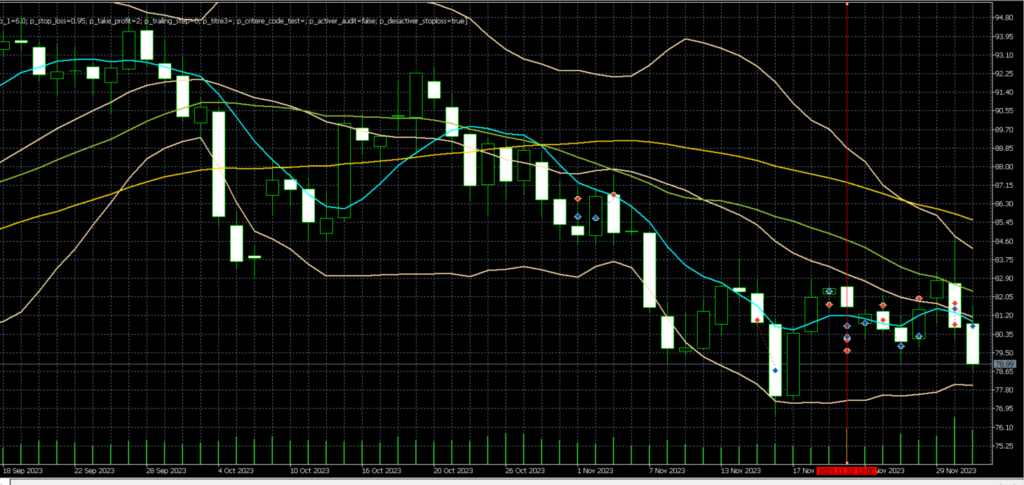
Graphique D1:
2 de ces trades perdants ont été émis le 22/11/23, sur une très forte bougie h4 baissière, avec des ouvertures de position visiblement très éloignés de la MM8.h4 (en bleu). En daily, on visualise également très bien le fait que ces trades étaient mal positionnés. Il est probable qu’un humain avisé n’aurait pas ouvert de trades à la vente à ce moment là. Le trade perdant du 30/11 semble correspondre au même schéma en H4, nous pouvons donc espérer écrire un arbre de décision qui engloberait ces 3 trades.
Des contrôles qui fonctionnent généralement bien consistent à mesurer les écarts aux moyennes mobiles, ainsi que leurs gradients, ceci souvent en conjonction avec d’autres observations. Parfois il est nécessaire de tester plusieurs variantes afin de trouver ce qui correspond le mieux.
L’observation permet donc d’émettre les premières hypothèses, puis une simulation sur la période globale de test doit être lancée afin d’identifier tous les trades impactés. Chaque hypothèse doit être testée pour être validée.
Dans ce cas, je remarque qu’en H4, les moyennes mobiles ne sont pas « rangées » dans le bon ordre, et le trade est lancé totalement à l’opposé. La MM50 est représentée en jaune, et la MM26 en vert. On a donc la MM8 > MM50 > MM26, ce qui n’est pas une configuration « propre », illustrant un mouvement récent fort dans le sens de l’achat. L’émission d’un trade à la vente, de surcroît mal positionné par rapport aux moyennes mobiles semble effectivement être un mauvais choix, aux probabilités de succès réduites.
Nous allons dans un premier temps émettre des critères les plus généraux possibles, puis ce sont les résultats de la simulation qui nous permettront d’affiner les choses.
On pourrait ainsi écrire pour la vente (ce sera l’inverse pour les achats):
Ce premier jet nous permet d’isoler 27 trades sur la période de 10 ans (sans nos trades de novembre), ce qui peut sembler faible mais toutefois suffisant pour pouvoir identifier des critères supplémentaires. On peut ajouter à cela nos 3 trades de novembre 2023 qui correspondent également à ce descriptif.
Cela constituera un arbre de taille assez réduite, mais nous pourrons toujours apprécier dans le futur que des trades ne soient plus émis dans une situation comparable. Hera est un robot déjà bien avancé en terme d’optimisation, donc à ce stade, il est normal que les trades gagnants soient majoritaires.
Pour ne pas perdre trop de trades positifs, nous allons voir si il est possible d’affiner un peu les choses. Même si il ne faut jamais s’obstiner à essayer de trouver une cohérence là où il n’y en a pas!
C’est là que le fichier .csv est indispensable.
Avec l’expérience, on peut identifier rapidement les valeurs caractéristiques extrêmes qui permettent de préciser les choses, le but étant de relier entre eux le plus de trades perdants, en excluant au maximum les trades positifs. La lecture des données conjuguée à la visualisation des trades sur la courbe, rend cette technique particulièrement efficace.
Dans cet exemple, les critères supplémentaires conservés vont être relatifs au positionnement du prix vis à vis de la mm8.mn1, de la mm4.mn1, et des gradients de moyenne mobile mm4.d1 et mm8.w1. Il serait quasiment impossible d’identifier ces informations avec leur seuil sans l’aide d’un reporting adapté.
Dans cet exemple relativement simple, la seule lecture du fichier de reporting s’est avérée suffisante, mais le plus souvent, il est nécessaire de recourir à des patterns graphiques pour parvenir à affiner les choses.
On pourrait ainsi écrire, toujours pour les ventes (les seuils sont ici à titre indicatif, ils doivent être déterminés sur des valeurs normalisées et apparaissent souvent très utiles pour quantifier la force d’une tendance ou l’importance d’un éloignement):
Ces nouveaux critères permettent d’identifier désormais les trades suivants (auxquels il faut toujours rajouter nos 3 trades perdants de novembre – s’agissant de jeux de données différents, historique tickstory vs historique récent metatrader, il n’est pas possible de les avoir sur un même graphique. La « fusion » des données doit se faire manuellement).
Nous avons conservé ainsi 10 trades (+ 3 trades de novembre), dont seulement 3 gagnants, qui seront désormais exclus par cet arbre de décision.
Les trades sur novembre suite à validation de cet arbre de décision sont ainsi plus « propres » qu’initialement. Il ne reste plus qu’un trade négatif, le 21/11 à 12h00, qu’il serait difficile de sécuriser. Un exemple de trade perdant « par malchance » sur lequel baser un arbre de décision ne semble pas être une bonne idée. S’acharner à vouloir exclure des trades perdants qui sont en toute objectivité bien placés nous ferait tomber dans l’écueil de l’over fitting.
Notre arbre de décision est ainsi achevé, d’une manière assez simple, puisqu’il n’a pas été nécessaire de lui associer des branches.
Quelques mots concernant les branches. Une branche est l’équivalent d’un « sauf si…. », et permet d’exclure d’un arbre de décision un ensemble de trades correspondant à une situation précise. Une branche, qui sera un ensemble de conditions favorables, va donc permettre l’exclusion de trades gagnants d’un arbre de décision.
Comme le dit souvent un de mes youtubeurs préférés, il est important de “comprendre ce qu’il se passe” (merci Tibo!).
Un leitmotiv à se répéter en boucle tous les matins…
Si vous en êtes arrivé au point où vous avez un robot qui applique votre stratégie, si vous regardez sur la courbe l’historique des signaux, vous verrez invariablement des trades qui ont été ouverts à des moments où ils n’avaient objectivement que très peu de chance de réussite. Il faut parfois changer d’échelle de temps pour s’en rendre compte. Un trade peut sembler pertinent en M15, puis qu’en on passe en H4 ou D1, on va s’apercevoir qu’on est bien en dehors des bandes de Bollinger, avec des signes évidents de retracement en cours au niveau du macd ou du stochastique.
Ainsi, pour arriver à “comprendre ce qu’il se passe”, la première chose est d’aller contrôler les différentes échelles de temps, surtout les échelles de temps supérieures (MN1, D1, H4).
Le fait d’observer un trade en particulier, pris isolément des autres trades générés par votre robot, n’a toutefois que peu d’importance. Ce qui nous intéresse, c’est la probabilité de succès ou d’échec d’un trade dans une configuration de marché donnée.
Pour connaître cette probabilité, il est indispensable de savoir générer un listing des trades émis, avec pour chacun d’eux la valeur de nos indicateurs préférés, les points gagnés ou perdus, ainsi que toutes les informations dont on peut avoir besoin. Notre ami Excel ou tout autre tableur de votre choix vous aidera alors à tirer toutes les conclusions dont vous avez besoin.
Cette possibilité de générer des fichiers de reporting est l’un des gros avantages de Metatrader sur les autres plateformes TradingView ou ProRealTime.
En MQL, la génération de fichiers est très simple. On commence par la génération de l’entête au niveau du OnInit(), dont voici un exemple ci-dessous:
Ce répertoire est vidé à chaque lancement d’une nouvelle simulation, donc si il disparaît, c’est normal. Si ce mode de fonctionnement ne vous convient pas, vous pouvez utiliser l’option “FILE_COMMON”, ainsi vos fichiers seront créés dans un répertoire permanent.
L’écriture des données spécifiques à chaque trade émis doit se faire au moment de la clôture du dit trade si l’on veut savoir notamment si ce trade est gagnant ou pas…
Comme on souhaite récupérer les informations de marché au moment de l’ouverture du trade, cela signifie donc que l’on doit stocker ces informations dès l’ouverture du trade, pour être en mesure de les restituer plus tard.
Ainsi, au niveau des fonctions permettant l’ouverture d’un trade achat/vente, on va venir mettre à jour un tableau conservé en sessions, avec toutes les données nous intéressant.
Il ne reste plus qu’à voir la mise à jour du fichier au moment de la clôture du trade.
Pour cela il est nécessaire de pouvoir exécuter une fonction à chaque fois qu’un trade se ferme, ce qui va s’avérer impossible si notre trade est fermé automatiquement par StopLoss ou TakeProfit. On doit donc pouvoir “hacker” ce fonctionnement, du moins pour les simulations.
Il y a probablement plusieurs façons de procéder, peut-être plus élégantes que celle que je vous propose ici, le principal est que cela fonctionne.
J’ai l’habitude de rajouter un paramètre de lancement “Désactiver stop loss (pour data report)”, variable “p_desactiver_stoploss”. Quand ce paramètre est activé, les stop loss/take profit ne sont pas définis au niveau des trades ouverts.
Voici ce que cela donne au niveau de la fonction de fermeture des trades pour la gestion des stop loss:
if (PositionGetDouble(POSITION_SL) == 0 && !p_desactiver_stoploss) { m_trade.PositionModify(ticket, MathRound(PositionGetDouble(POSITION_PRICE_OPEN) – p_stop_loss * m_symbolPointVal), PositionGetDouble(POSITION_TP) ); } // Stop loss automatique au cas où la mise à jour du SL ait échoué if (points_en_cours < -1 * p_stop_loss) { if (PositionClose(ticket, “SL”)) UpdateReporting(currentTrade, “SL”); }
Il reste à créer la fonction de mise à jour du fichier de reporting:
Ce n’est bien entendu qu’un exemple, à vous de constituer ce reporting avec les informations dont vous avez besoin, vos indicateurs préférés, etc…
Pour ma part j’aime bien avoir un aperçu des points max/pertes max durant la vie de chaque trade, car cela permet de voir les optimisations à apporter au niveau de la stratégie de sortie.
J’utilise aussi des commentaires à l’ouverture du trade mais aussi à la fermeture afin d’identifier les éléments déclencheurs d’une ouverture et d’une fermeture dans le cas de stratégies avancées.
Je pense avoir dit ici le principal.
Cet outil assez simple est particulièrement puissant et incontournable. Je l’utilise systématiquement pour être en mesure d’identifier les différentes configurations de marché, notamment celles qu’il vaut mieux éviter.
Avec l’habitude, on arrive parfois à lire le marché juste sur la base de ces données et sans même regarder la courbe, même si l’aspect graphique s’avère indispensable dans de nombreuses situations. Cela permet de détecter rapidement la présence d'”outliers” sur certains indicateurs, c’est à dire des valeurs inhabituelles permettant de comprendre que nous sommes dans une situation de marché particulière.
C’est cette complémentarité entre “datas” et “lecture d’un graphe” qui donne toute sa puissance à cette méthode. Cela permet d’apprendre au fil de l’expérience les configurations qui fonctionnent, et celles qui fonctionnent beaucoup moins. On découvre aussi que rien n’est aussi simple qu’il n’y paraît. Une configuration de marché peut nous sembler particulièrement dangereuse en analysant un cas particulier, mais en regardant de manière globale, sur un historique de 10 ans, et sur plusieurs actifs, on peut se rendre compte que c’est beaucoup plus subtil que cela, et que finalement, cela se passe plutôt bien dans la plupart des cas. C’est là où l’analyse des données collectées va nous aider à comprendre ce qui différentie un cas “qui marche”, d’un cas “qui ne marche pas”. Ce sera peut-être en regardant les gradients de moyennes mobiles, les distances à ces moyennes mobiles, ou d’autres indicateurs.
Nous allons voir maintenant comment booster radicalement la vitesse d’exécution de nos simulations via le testeur de stratégie de Metatrader.
Ce point est particulièrement crucial car pour mener à bien l’optimisation d’un robot de trading, on va être amené à lancer un grand nombre de simulations quotidiennement, ce qui n’est pas possible si chaque simulation prend plusieurs minutes, ou pire plusieurs heures.
Quand on débute sur Metatrader, puisqu’on manque d’éléments de comparaison, on peut trouver normal que cela dure plusieurs minutes, et s’y habituer.
Pour vous donner un ordre d’idée, je suis amenée à lancer plus d’une centaine de simulations sur plus de 10 ans chacune, par jour…. Chacune de ces simulations prend une trentaine de secondes. C’est donc une action que je peux exécuter très régulièrement afin de tester de nouveaux critères.
Cette vitesse d’exécution est un élément clé de la réussite de votre projet de développement d’un robot de trading.
Voyons maintenant comment optimiser ce processus:
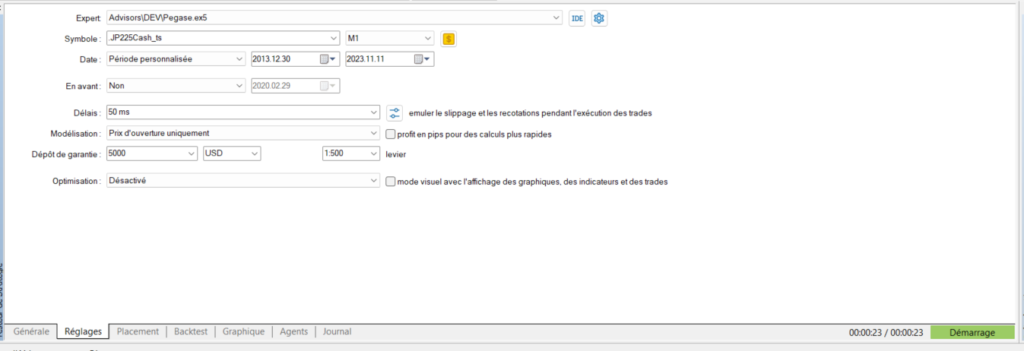
Au niveau de la fenêtre de lancement de votre simulation, les paramètres clés sont les suivants:
Modélisation: “Prix d’ouverture uniquement”. Dans ce mode, le code ne sera exécuté qu’une fois par bougie et non pas à chaque tick, ce qui va réduire le temps d’exécution de manière considérable. Bien entendu, ce mode va entraîner une approximation des résultats obtenus, mais si votre stratégie est basée sur des échelles de temps en h1, h4, ou d1, cette approximation devient tout à fait acceptable. C’est un des autres grands intérêts de bannir les signaux sur les toutes petites échelles de temps. Vous avez toujours la possibilité, de temps à autre, de lancer une simulation sur chaque tick, mais plutôt en soirée pour que cela tourne tranquillement pendant la nuit…
Optimisation: décocher “mode visuel avec l’affichage des graphiques (…)”. Cette option est également très gourmande et devient inutile notamment si l’on génère des fichiers .csv avec l’historique enrichi de nos trades, point qui fera l’objet d’un autre article.
Un autre point important afin d’optimiser vos simulations se situe au niveau du code, notamment de votre façon de coder. Quand à mes débuts je cherchais comment accélérer mes scripts sur les forums de discussion, j’ai surtout vu des échanges concernant l’optimisation des indicateurs, mais selon ma propre expérience, l’impact est dérisoire par rapport aux conseils ci-dessus.
Toutefois, si vous êtes développeur, vous aurez probablement envie d’écrire un programme en utilisant à fond les concepts “orientés objets”, en créant de jolies classes que vous allez séparer dans des fichiers. Je vous déconseille vraiment de faire ainsi, car cela va ralentir considérablement l’exécution de vos scripts. Mieux vaut créer quelques fonctions que vous mettrez dans votre fichier principal et ne pas chercher à aller plus loin. Donc, restez le plus simple possible dans vos scripts.
D’autres éléments peuvent venir ralentir vos scripts de manière importante. Par exemple, le fait d’utiliser des bougies Heikin Ashi est extrêmement pénalisant.
Concernant vos indicateurs, personnellement j’en utilise un nombre assez important (4 moyennes mobiles, macd, rsi, bollinger, atr, sur toutes les échelles de temps entre MN1 et H1), et cela ne pose aucun problème. Je n’ai aucun scrupule à en rajouter quand j’en ai besoin.
Comme dit plus haut, si vous suivez ces conseils, une simulation sur 10 ans ne devrait pas excéder 30 secondes.
En matière de prédiction, rien n’est plus important que de disposer de données de qualité, et en quantité suffisante. Pour réaliser un robot robuste, c’est à dire adapté au plus grand nombre de situations de marché différentes, un test réalisé sur 1 ou 2 ans sera loin d’être suffisant.
Si vous avez opté pour une stratégie dont le principe est volontairement de générer des trades de manière quasi aléatoire, en espérant une balance plutôt positive in fine, ce point aura peut-être moins d’importance, mais vous devriez tout de même être curieux de savoir si vos réglages fonctionnent de manière générale, ou si ils sont adaptés juste sur ces derniers mois, avec par exemple un contexte de croissance forte et régulière.
Si votre robot est basé sur des signaux d’achat/vente clairement identifiés par une stratégie donnée, l’analyse des tendances aux différentes échelles de temps va alors permettre d’identifier les configurations de marché favorables à notre stratégie, de celles qui le sont beaucoup moins, et bien entendu, d’agir en conséquence.
Pour cela, il est important de regarder les tendances hebdomadaires et mensuelles qui ont un impact très important (que vous vous en soyez rendu compte ou pas encore…), et qui ne peuvent s’étudier que sur plusieurs années.
Restreindre son analyse à 1 ou 2 années comme beaucoup le font fait perdre une quantité d’informations pourtant très utile.
La récupération d’historiques suffisants est donc l’une des premières préoccupations à avoir, mais malheureusement, c’est un sujet rarement évoqué sur les forums.
Voyons donc tout cela en détail.
Tout d’abord, il est important de comprendre que par défaut, les historiques disponibles sur Metatrader sont largement incomplets. Si par exemple en mensuel vous allez pouvoir remonter 20 années au-delà, en hebdomadaire vous n’aurez peut-être plus que 10 années, puis au fur et à mesure que vous allez baisser dans les échelles de temps, la taille de l’historique va diminuer. Ces valeurs vont en outre varier d’un actif à un autre, et d’un broker à l’autre. Sur l’échelle à 1 minute, vous n’aurez plus que quelques mois. Et si vous descendez jusqu’aux ticks, il faut savoir que Metatrader inclut un système de simulation de ticks. Vous n’aurez donc probablement pas des ticks réels mais des ticks simulés.
Voyons maintenant comment améliorer le fonctionnement de base de Metatrader concernant les historiques de données.
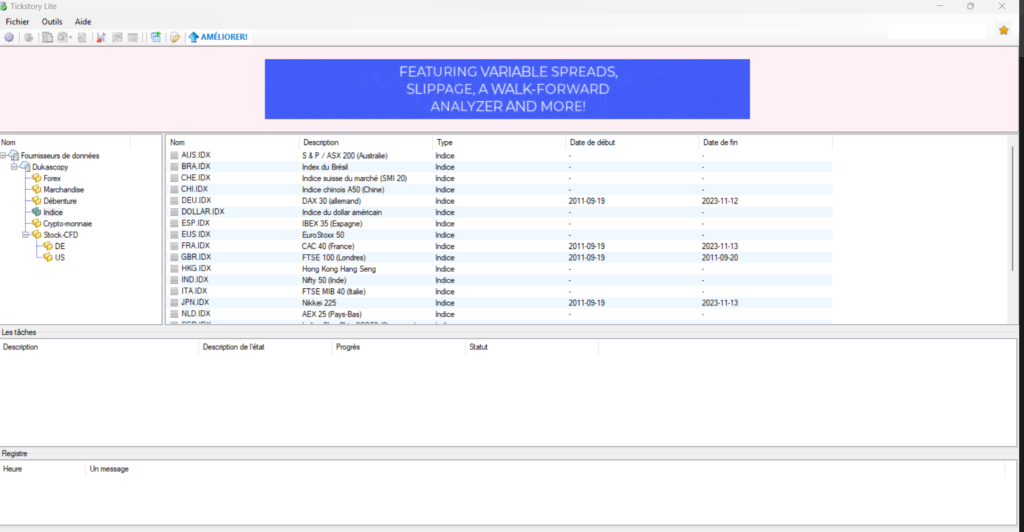
Tick Data Suite et Tick Story sont 2 fournisseurs d’historiques de données financières parmi les plus cités. Tick Data Suite est un service payant (mais accessible), avec une version d’essai gratuite de 15 jours qui vous permet déjà de télécharger pas mal de données. Tick Story est un service gratuit, mais avec une version payante permettant notamment d’accélérer grandement les téléchargements qui sinon peuvent prendre facilement plusieurs heures.
Je vais par la suite utiliser Tick Story pour les explications, mais la procédure est quasiment la même pour Tick Data Suite, seule change l’interface de téléchargement.
Dans les 2 cas, il est possible de récupérer des historiques de 10 à 20 ans selon les actifs. Est-ce suffisant? Pas évident, nous verrons dans un autre comment y remédier en réalisant des optimisations sur plusieurs actifs.
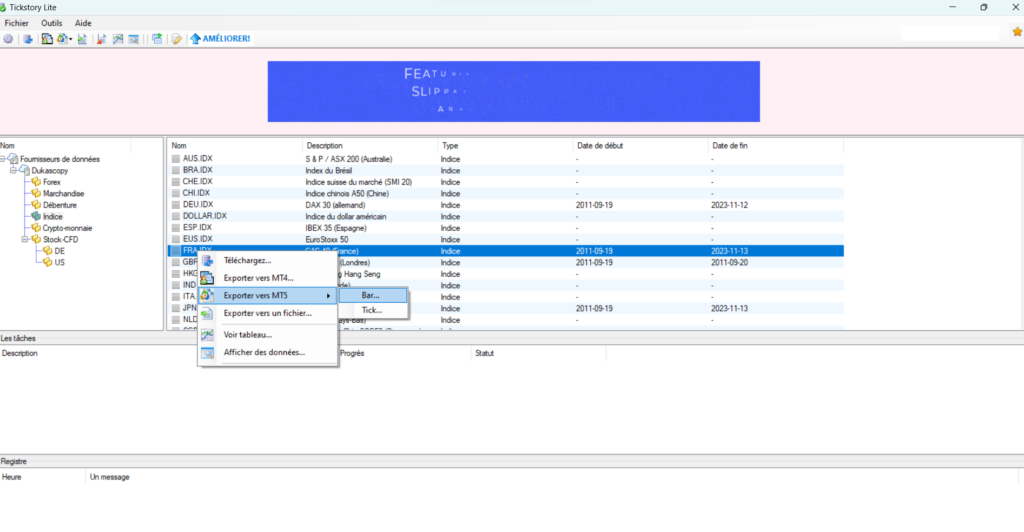
Après avoir installer l’interface Tick Story proposée depuis leur site, vous avez rapidement accès à l’ensemble des actifs disponibles, forex, indices, crypto, commodities, etc… si vous ne trouvez pas votre bonheur, vous pouvez toujours essayer auprès d’un autre fournisseur de datas.
L’étape suivante consiste, avec un clic droit, à sélectionner votre actif, puis choisissez “Exporter vers MT5”, puis l’option “Bar” ou “Tick”. Les fichiers Ticks sont bien évidemment beaucoup plus volumineux que les simples Bars. Nous verrons dans un prochain article que les simulations sur Ticks sont également beaucoup plus lentes que sur les Bars. Vous pouvez dans un premier temps prendre l’option “Bar”, et si vous avez besoin plus tard de confirmer votre stratégie de manière plus précise en utilisant les Ticks, vous saurez où les trouver.
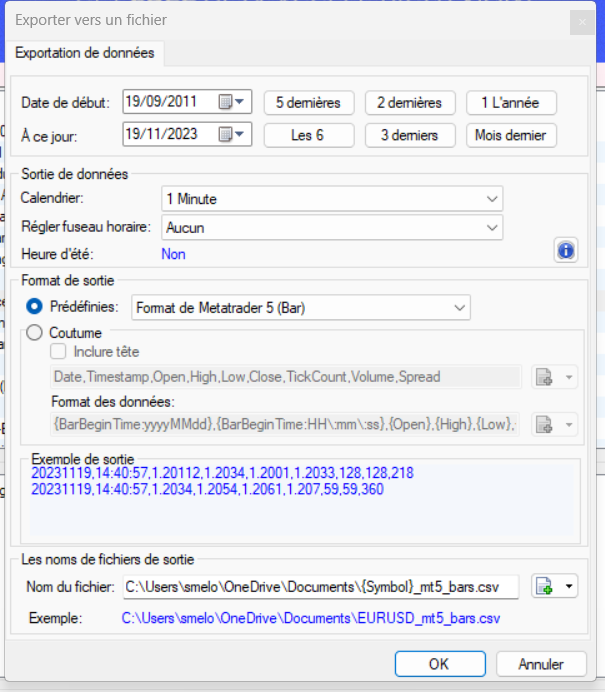
Une fois l’option “Bar” choisie, l’utilitaire de téléchargement apparaît. La période proposée par défaut est la période totale disponible. Ici, pour le DAX40, on a accès aux données depuis 2011, ce qui fait un peu plus de 10 années de données. Est-ce suffisant? Probablement pas, mais c’est tout ce qu’il est possible d’avoir pour commencer en gratuit.
Dans la ligne “Calendrier”, vous pouvez choisir le timeframe à télécharger. Je vous conseille le 1 minute ou le 5 minutes mais il vaut mieux ne pas aller au-delà.
La ligne “Régler le fuseau horaire” a une importance capitale que je n’ai comprise que tardivement malheureusement. Si vous laissez la valeur par défaut, sans chercher à vous aligner avec le fuseau horaire du serveur de votre broker, vous risquez d’avoir des décalages entre les courbes “temps réel” et les courbes issues de vos historiques. Cela peut avoir plusieurs incidences. Par exemple si votre stratégie doit respecter à des heures précises, vous n’allez tout simplement pas tester sur les bonnes tranches d’heures. Une autre incidence sur laquelle on peut facilement passer à côté pendant des années, est qu’un décalage d’une heure seulement entre les heures de votre historiques et les heures de votre broker peut provoquer l’apparition d’une bougie le dimanche (absente sur les courbes temps réel), ce qui va venir chambouler tous vos calculs d’indicateurs, positionnement dans votre stratégie, optimisation, etc… Autant dire que vous n’aurez qu’à tout reprendre depuis le début.
Pour ne pas vous tromper, il est préférable de télécharger seulement les derniers jours, de charger sur metatrader (nous allons voir maintenant comment faire), puis de comparer avec vos courbes réelles. Si vos bougies sont décalées, c’est que vous n’avez pas le bon fuseau horaire. Une fois que vous êtes certain du bon fuseau horaire à télécharger, vous n’avez plus qu’à lancer le téléchargement et à patienter!
Chargement des données dans Metatrader
La procédure est assez simple, quand on sait comment s’y prendre.
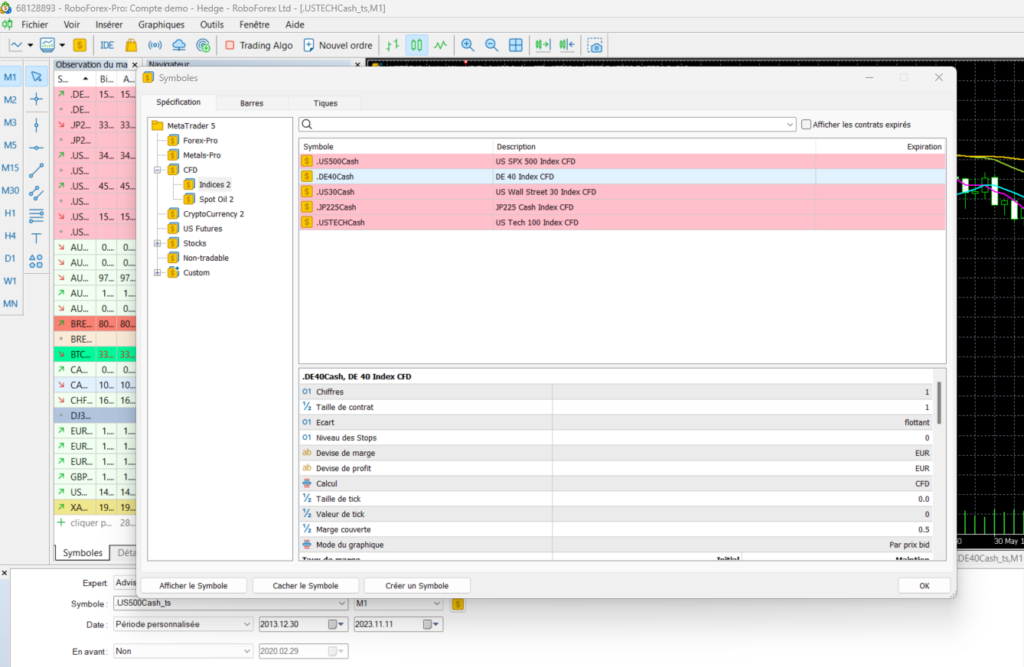
L’idée consiste à créer un nouveau symbole que l’on va venir alimenter avec nos historiques. Ce symbole sera ensuite utilisable directement depuis le testeur de stratégie comme si il s’agissait d’un symbole fourni par votre broker.
Depuis la barre d’outils, en haut à gauche, ou depuis l’onglet “Voir / Symboles”, vous lancez la fenêtre “Symboles”. Vous choisissez l’actif désiré, ici le DAX, en cliquant dessus, les informations relatives à cet actif apparaissent en bas. Puis vous cliquez sur “Créer un symbole”. Le fait de pré-sélectionner votre actif va permettre de récupérer toutes les informations qui lui sont relatives, et donc d’éviter de les saisir par la suite.
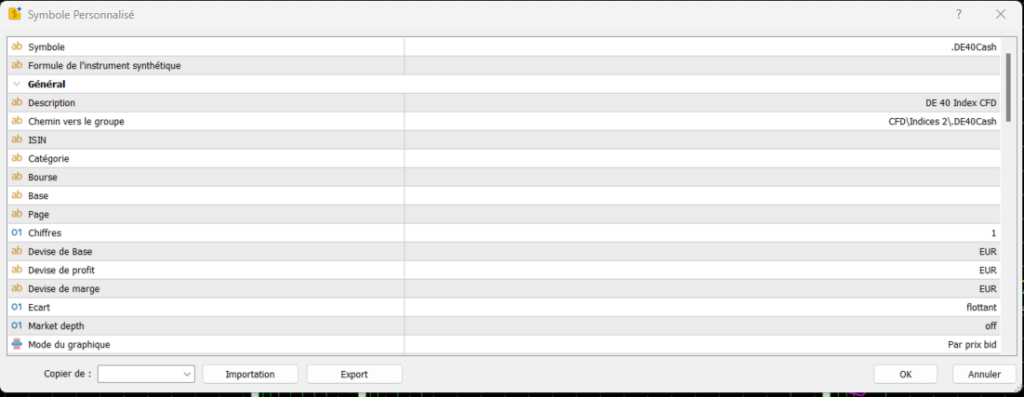
La fenêtre “Symbole personnalisé” apparaît alors. Il est préférable d’ajouter une extension “_ts” par exemple pour “tickstory” au nom de votre symbole afin de tracer l’origine des données et ne pas risquer de le confondre avec un symbole “réel”.
Une fois créé, votre symbole apparaîtra dans la rubrique “Custom”.
La dernière étape consiste à uploader votre historique. Pour cela, il vous suffit de cliquer sur le bouton “Barres” en haut de cette même fenêtre, puis sur le bouton “Importer des Barres”.
Une fois arrivé là, vous avez presque fini, mais une dernière vérification très importante s’impose: le montant des spreads. Les historiques contiennent en effet en dernière colonne le montant du spread applicable, mais il peut arriver un que cette valeur, qui dépend notamment du tickvalue configuré sur votre symbole, ne corresponde pas du tout aux spreads réels appliqués par votre broker. J’ai constaté des écarts équivalents à un facteur de 10, ce qui bien sût n’est pas acceptable. Pour s’assurer qu’il n’y a pas de soucis à ce niveau, le mieux est de lancer un robot dans le testeur de stratégie qui va afficher l’écart entre votre ASK et votre BID. Vous faîtes la même chose sur votre symbole réel. Si vous avez effectivement un facteur 10 de différence, vous devez alors ouvrir votre fichier d’historique sur un bon vieux excel et modifier la valeur de la dernière colonne en conséquence.
Il va de soi que sur un historique de 10 ans, le montant du spread a forcément évolué dans le temps, en même temps que la valeur de l’actif en question. C’est donc à vous de faire le choix d’utiliser une valeur fixe, un pourcentage, ou autre. Toutefois si vous avez des stratégies en daily, avec des trades sur plusieurs journées, une valeur approximative du spread de quelques points n’aura que peu d’influence sur l’évaluation de la performance générale. Si vous faîtes du scalping, ce n’est bien évidemment pas la même histoire!
Une fois le fichier modifié, vous pouvez le téléverser à nouveau par la même procédure.