Optimiser un robot c’est bien, mais croire que la couche d’optimisation sera suffisante et ainsi négliger la couche de money management, c’est un peu comme sauter en parachute, sans parachute de secours… C’est vrai que cela peut bien se passer la plupart du temps, mais est-ce une raison pour négliger la sécurité?
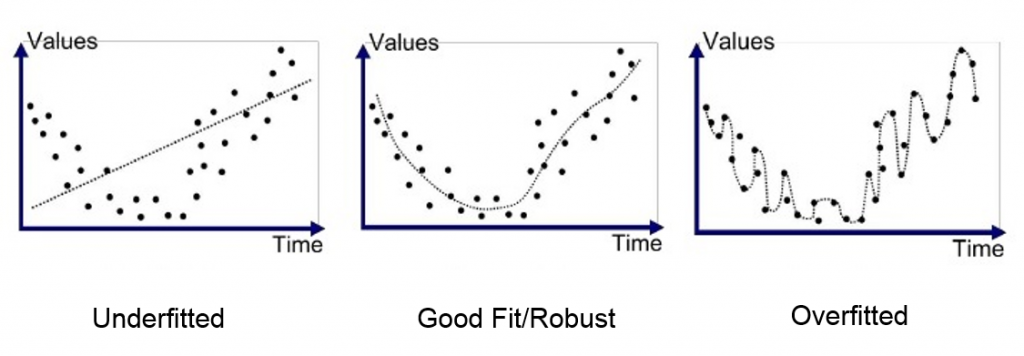
Nous allons voir ici à travers quelques exemples comment mettre en œuvre des couches supplémentaires, indépendantes de la couche d’optimisation, et dont le but ne sera pas d’augmenter les performances mais de réduire les risques pour tous les cas où l’optimisation aura failli à sa mission. Ces couches supplémentaires auront d’ailleurs souvent pour effet de réduire les gains théoriques. Il s’agit de l’éternelle rivalité entre performance et robustesse, 2 notions fondamentales dans tout système complexe.
Il s’agit ici d’observer le comportement de son robot, et principalement les situations où cela se passe mal. Le premier réflexe sera de revoir sa couche d’optimisation, et c’est important de le faire bien évidemment, mais il faut aussi prendre le temps d’analyser ces défaillances et de se demander comment on aurait pu gérer cela différemment, pour que les pertes subies soient réduites. Se poser ces questions et y trouver des réponses est fondamental car il y aura toujours dans l’avenir des situations qui ne seront pas traitées correctement par la couche d’optimisation.
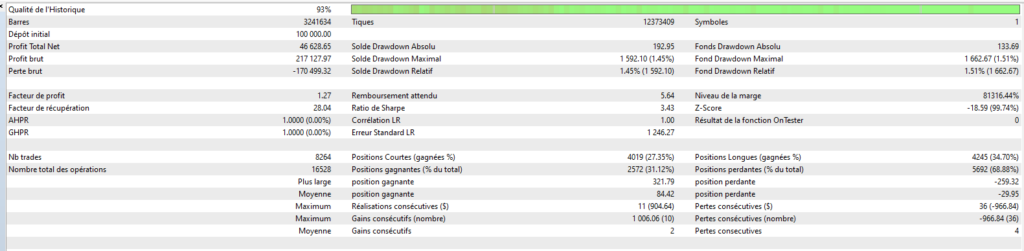
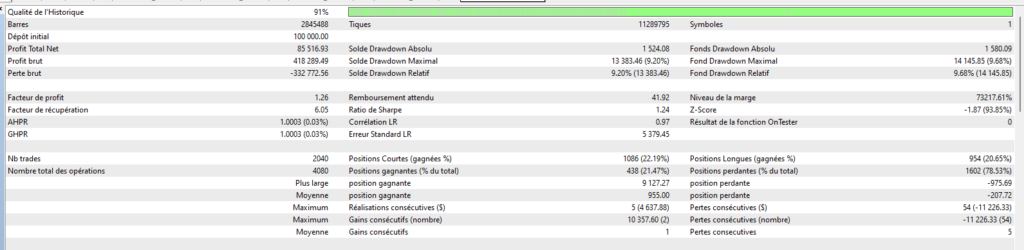
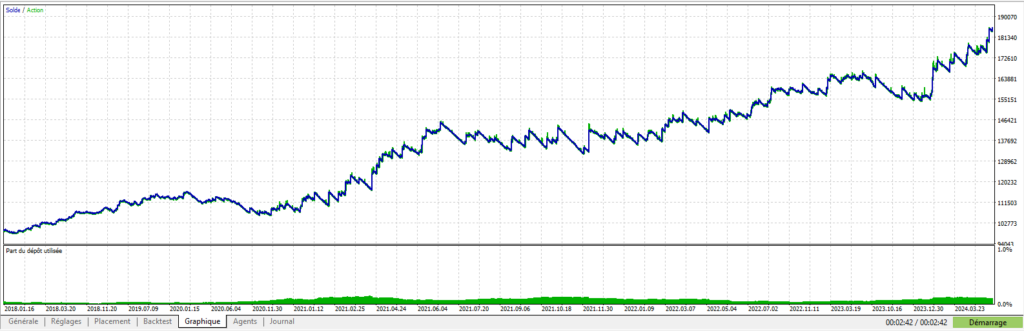
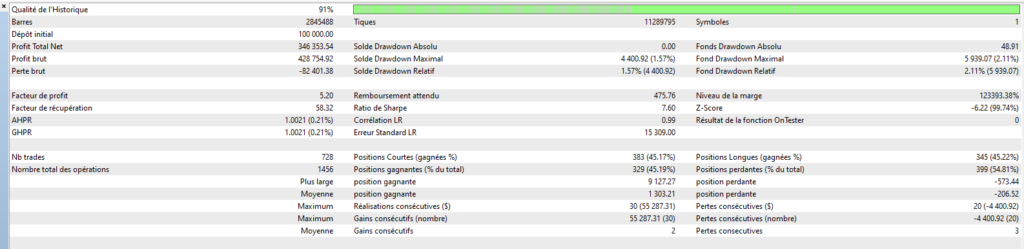
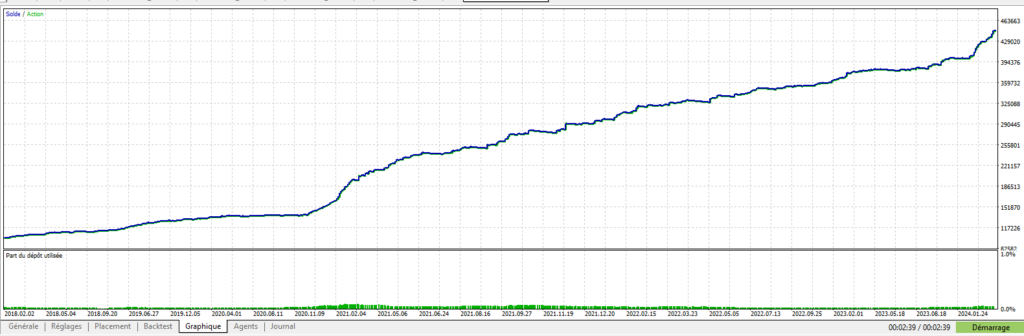
Pour que l’on puisse rentrer dans le vif du sujet, je vais vous donner quelques cas concrets que j’ai mis en œuvre sur mon dernier robot Cassiopée EURUSD dont je vous parlerai plus en détail dans un prochain article.
Pour bien comprendre le contexte de ce robot, il est important de préciser que ce robot a une moyenne de 10 trades quotidiens, et un SL = 15 x TP, avec un % de trades gagnants dépassant les 95%. Les pertes sur SL sont donc redoutées, d’autant plus que le robot autorise plusieurs trades simultanés… Sur le papier, on pourrait se dire qu’une telle approche est trop risquée, mais comme je suis d’un naturel curieux, et au vu des performances très intéressantes que l’on peut espérer d’un tel robot, j’ai choisi de relever le défi. Et cela passe ici, inévitablement, par une réflexion très poussée sur tous les moyens que l’on peut mettre en œuvre pour éviter de se retrouver dans la situation fâcheuse de 5 trades simultanés qui courent vers leur SL….
Les parachutes de secours que je vais vous présenter ci-dessous sont donc adaptés à ce contexte particulier.
- Couples SL/TP phase optimisation et production différents
L’une des premières bonnes pratiques en matière d’optimisation, à mon sens, est d’appliquer lors de la phase d’optimisation des valeurs à nos TP et SL plus restrictifs que ceux que l’on souhaitent appliquer en production. Cette bonne pratique n’est pas du money management à proprement parlé, mais je considère qu’il s’agit là du premier “parachute de secours”, que l’on doit prévoir au tout début de notre phase de développement.
Si l’on reprend l’exemple de Cassiopée:
– phase d’optimisation: TP = 1.5 et SL = 5
– phase production: TP= 1 et SL = 15
Cela va permettre, lors de la phase d’optimisation, de se concentrer sur les trades les plus intéressants, en excluant les trades perdants, et les trades gagnants de justesse. En pratique, le fait de multiplier le SL par 3 en production va permettre d’augmenter significativement le % de trades gagnants.
On se retrouve toutefois avec un rapport de 15 entre le SL et le TP, ce qui va demander la mise en œuvre d’un money management bien réfléchi, c’est ce que nous allons voir par la suite. - Augmentation de la taille de position suite à une perte
Ce rapport de 15 entre TP et SL signifie qu’après une perte sur SL, 15 trades gagnants seront nécessaires pour récupérer. Toutefois, n’oublions pas que l’une des caractéristiques de ce robot est le % de trades gagnants très élevé, et c’est ce que nous allons mettre à profit ici par une méthode très simple: la multiplication par 2 de la taille de position pour les trades consécutifs à une perte. Ce ne sont alors plus que 8 trades gagnants qui seront nécessaires, et non plus 15. Dans la plupart des cas, cette technique sera profitable, mais il y a toujours un risque qu’une autre perte sur SL survienne alors que les tailles ont été augmentées. Ce risque doit donc être bien pris en compte lors du calibrage du robot, car on doit toujours appliquer la règle d’or: le dimensionnement d’un robot (détermination des tailles de position) doit se faire par rapport aux risques pris et non par rapport aux gains espérés!
Pour ne pas rentrer dans le danger que représentent les martingales, ce palier x2 n’est appliqué qu’une seule fois. - Clôture de trades perdants avant le SL si dépassement de l’objectif de gain journalier atteint.
Cette approche est intéressante dans le cas de robots ayant des SL très importants par rapport au TP comme c’est le cas dans notre exemple. Les trades “foireux” vont ainsi traîner généralement plusieurs jours avant d’aller taper le SL ou de revenir sur le TP, ce qui laisse le temps d’intervenir dessus de multiples manières. Dans le cas d’un robot qui autorise plusieurs trades simultanés, la présence de ces trades foireux pendant une période de temps pouvant être assez longue ne va pas empêcher le robot de continuer à cumuler des gains. Un paramètre a ainsi été ajouté, permettant de définir le % de gains journaliers visé, que nous fixerons ici à 2%. On peut donc considérer que tous les gains cumulés au-delà de cet objectif sur les 10 derniers jours par exemple, représentent un pactole que l’on est libre d’utiliser à notre guise, notamment pour venir clôturer des trades “foireux” et ainsi abaisser le risque global régulièrement. Par exemple, on peut considérer qu’un trade dont les pertes dépassent le SL de 5 que l’on s’était fixé en phase d’optimisation représente un danger potentiel. Il est donc préférable de le clôturer si cela ne vient pas compromettre notre objectif de gains journaliers.
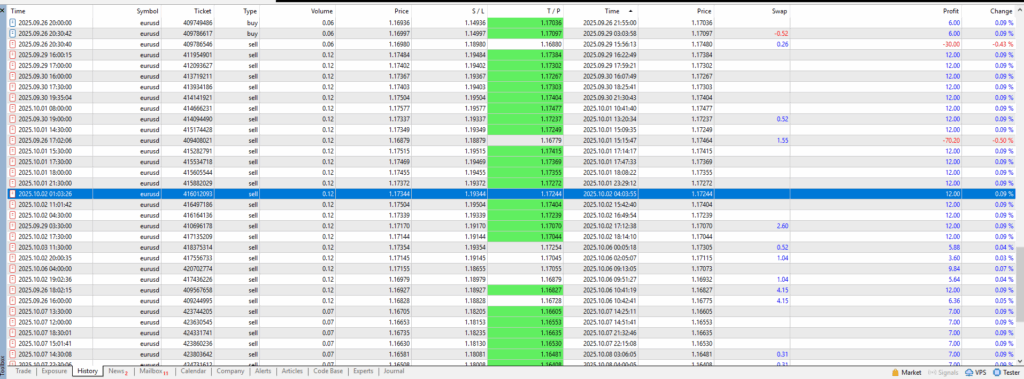
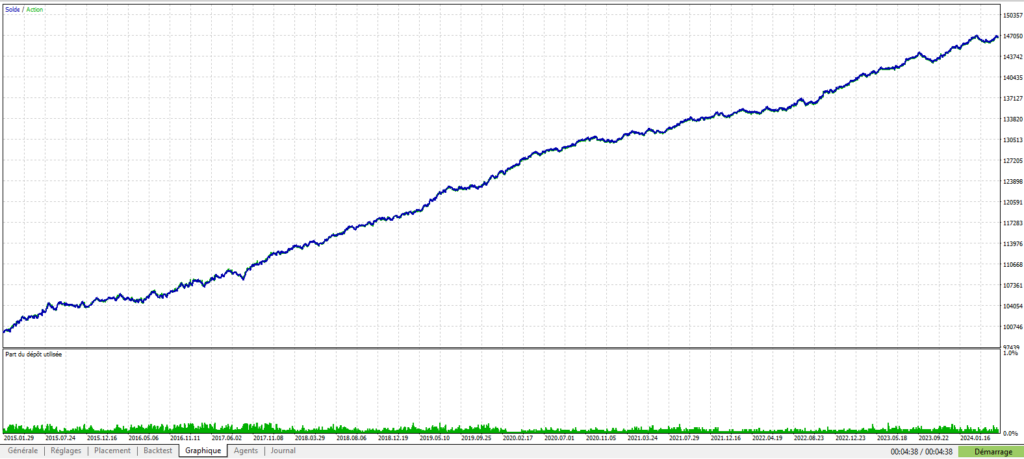
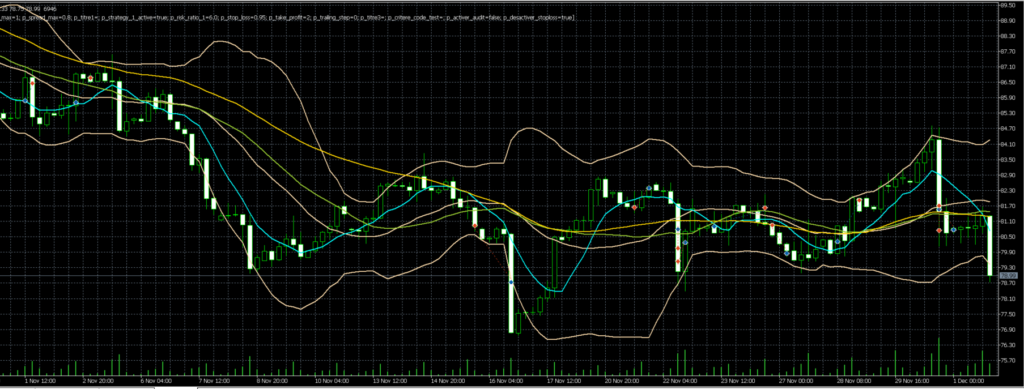
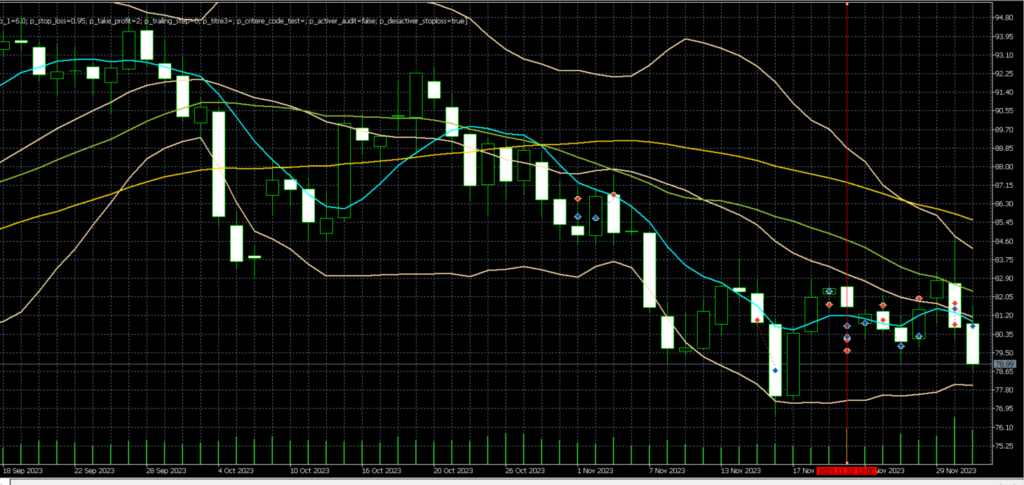
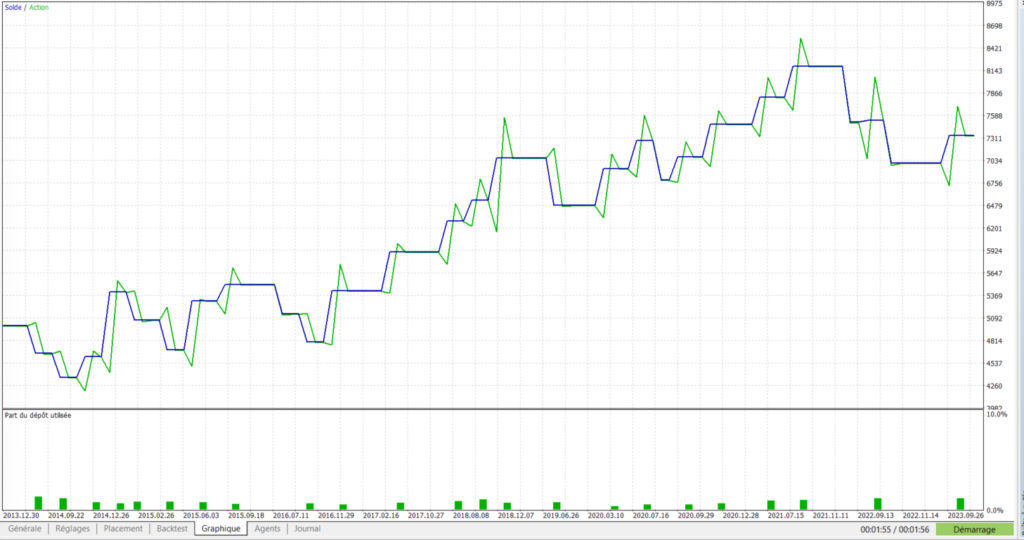
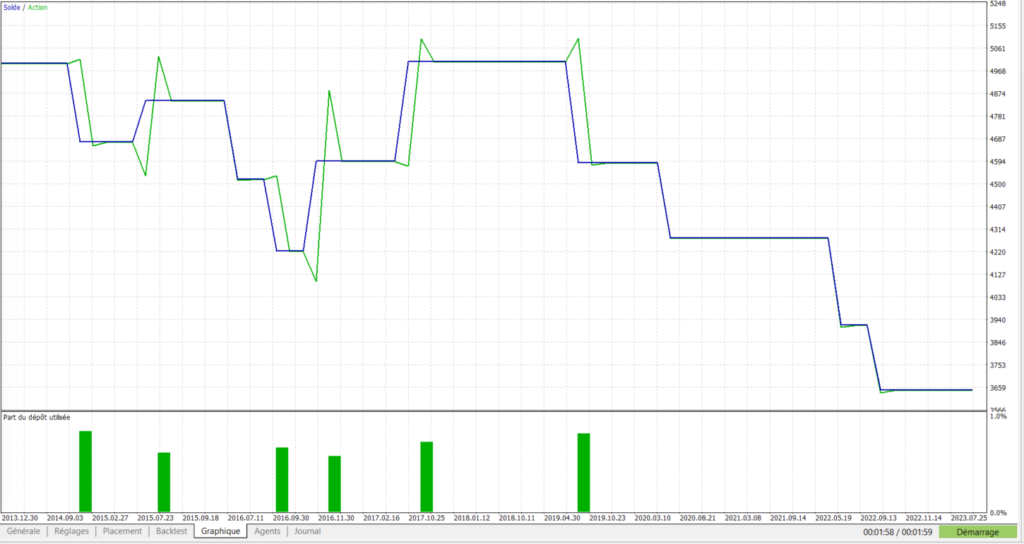
On observe ici l’illustration du comportement induit par les 2 méthodes précédentes, à savoir l’augmentation de la taille de position suite à une perte, et la clôture de trades “foireux” avant qu’ils n’aillent atteindre le SL qui leur a été assigné.
4. Augmentation du delta entre trades au-delà de 3 trades ouverts
Comme nous sommes dans le cas d’un robot autorisant de nombreux trades simultanés, la notion de delta de prix minimale entre trades a été ajoutée afin de ne pas ouvrir plusieurs trades sur un même niveau de prix, ce qui n’aurait pas de sens. Le problème rencontré fréquemment se situe lors des retournements de tendance, car le système peut alors ouvrir plusieurs trades en contre tendance, ce qui aura pour effet une augmentation du niveau de risque pas toujours très agréable à vivre. Pour limiter ces trades contre tendance de manière simple, on peut alors décider qu’au delà de 3 trades ouverts dans une direction donnée, le delta de prix minimal imposé sera multiplié par 3.
5. Détermination des niveaux de risque
Il s’agit ici d’une pratique un peu plus complexe à mettre en œuvre mais également très efficace.
La phase d’optimisation consiste à écrire des “arbres de décision“, chaque arbre contenant des “branches“.
Pour faire simple, un arbre correspond à une configuration de marché définie de manière assez générale. Par exemple, on va vouloir étudier les zones de marché où notre stochastique hebdomadaire a atteint la zone des 80/20, tout en présentant des signes de retracement et un placement pas très favorable par rapport à une moyenne mobile donnée.
Si l’on regarde une telle configuration sur un historique de données de 10 ans, on va obtenir un lot de trades dont certains seront perdants, et d’autres gagnants. L’optimisation de cet arbre peut alors commencer par la rédaction des “branches” qui vont permettre de définir des exceptions pour lesquelles les trades seront majoritairement gagnants. Les branches permettent donc de définir les situations d’exception pour lesquelles l’arbre ne sera pas appliqué.
La rédaction de ces branches passe inévitablement par l’observation des données passées, avec l’espoir qu’elles seront également pertinentes pour les données à venir.
C’est là que se situe le danger, car il y a une multitude de manières d’écrire une branche, en privilégiant tel ou tel critère, telle ou telle échelle de temps, etc… et surtout on va baser nos choix sur les trades à notre disposition, donc les trades passés. L’apparition de nouveaux trades peut potentiellement remettre en question les choix qui auront été faits. Ainsi, une branche peut se montrer défaillante si elle autorise le passage de trades perdants alors qu’ils auraient pu être bloqués si la branche avait été écrite différemment.
Ce risque de défaillance des branches sera toujours présent, malgré tout le soin que l’on pourra apporter à leur écriture.
Pour en réduire les effets potentiels, l’idée est donc d’évaluer le risque que représente chaque arbre avant que l’optimisation ne lui soit appliquée, c’est à dire avant la rédaction des branches, et d’appliquer des règles de trading différentes en fonction de ce niveau de risque.
Pour Cassiopée, j’ai ainsi défini 3 niveaux de risque:
– 1: risque faible: on applique les règles de trading normales
– 2: risque modéré: on abaisse les tailles de position de 25% par rapport à la normale
– 3: risque élevé: on abaisse les tailles de position de 25% par rapport à la normale, on n’applique pas de x2 suite à une perte, et on limite le nombre de trades à 1 par tranche de 12h
Reste maintenant à déterminer ces niveaux de risque pour chacun de nos arbres.
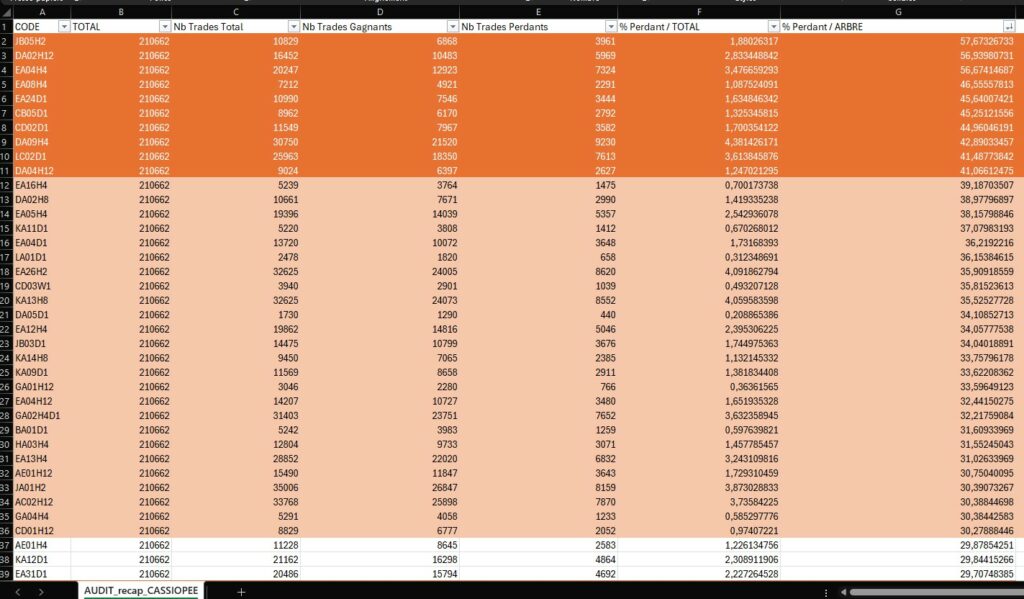
Ci dessus voici le type de fichiers qui peut nous aider dans cette tâche. Il représente les données statistiques collectées sur les 210662 trades de notre jeu de simulation, en fonction de chacun de nos arbres de décision.
Chaque arbre est codifié et peut être étudié de manière indépendante.
Par exemple, si un trade passe par l’arbre “JB05H2”, il aura environ 57% de chance d’être perdant (avant application des branches), ce qui est énorme. Nous sommes donc clairement dans une zone à haut risque, et devons rester très vigilant si jamais une branche de cet arbre venait à autoriser un trade. On va donc lui affecter un niveau de risque de 3.
Pour conclure ..
Pour terminer cet article, je voudrais revenir sur l’importance de distinguer les différentes phases de développement d’un robot de trading, que sont la phase d’optimisation visant à augmenter les performances, et la phase d’observation permettant l’élaboration des règles de money management adaptées à notre stratégie, et dont le but est d’augmenter la robustesse finale du robot (souvent en sacrifiant un peu de la performance théorique).
Les règles présentées ici ne sont que des exemples, d’autres parades peuvent être trouvées et mises en œuvre selon la stratégie adoptée par le robot, il s’agit de faire preuve de créativité, et de prendre le temps d’observer notre robot, et tout particulièrement les moments où les choses tournent mal.
On n’y reviendra jamais assez, mais c’est aussi pour toutes ces raisons qu’une phase d’observation/ajustement de plusieurs mois est nécessaire pour valider le comportement d’un robot et évaluer notamment sa robustesse en situation réelle (données temps réel sur compte démo).